分数分析
分数分析提供了一种轻量、零配置的方式,让你开箱即用地分析评估数据。无论你是在验证不同 LLM judge 是否产出一致结果、检查人工标注与自动化评估的对齐情况,还是在探索分数分布和趋势,分数分析都能帮你建立对评估流程的信心。
为什么使用分数分析?
分数分析是对 Litefuse 实验 SDK 和自助仪表盘的补充,提供即时、零配置的分数分析能力:
- 轻量配置:无需配置 —— 分数接入后立刻就可以分析
- 快速验证:比较不同来源的分数(例如 GPT-4 与 Gemini 作为 judge),衡量一致性、确保可靠性
- 开箱即用的洞察:可视化分布、跟踪趋势、发现相关性,无需自定义仪表盘
- 统计严谨:提供 Pearson 相关系数、Cohen’s Kappa、F1 等指标,并附带解读说明
对于需要自定义指标或复杂比较的高级分析,请使用实验 SDK 进行更深入的研究。
快速开始
前置条件
确保你的 Litefuse 项目中已经有分数数据,可以来自任意一种评估方法:
- 人工标注
- LLM-as-a-Judge 评估
- 通过 SDK 或 API 接入的自定义分数
进入分数分析
- 在 Litefuse 中进入你的项目
- 在导航菜单中点击
Scores - 选择
Analytics标签页
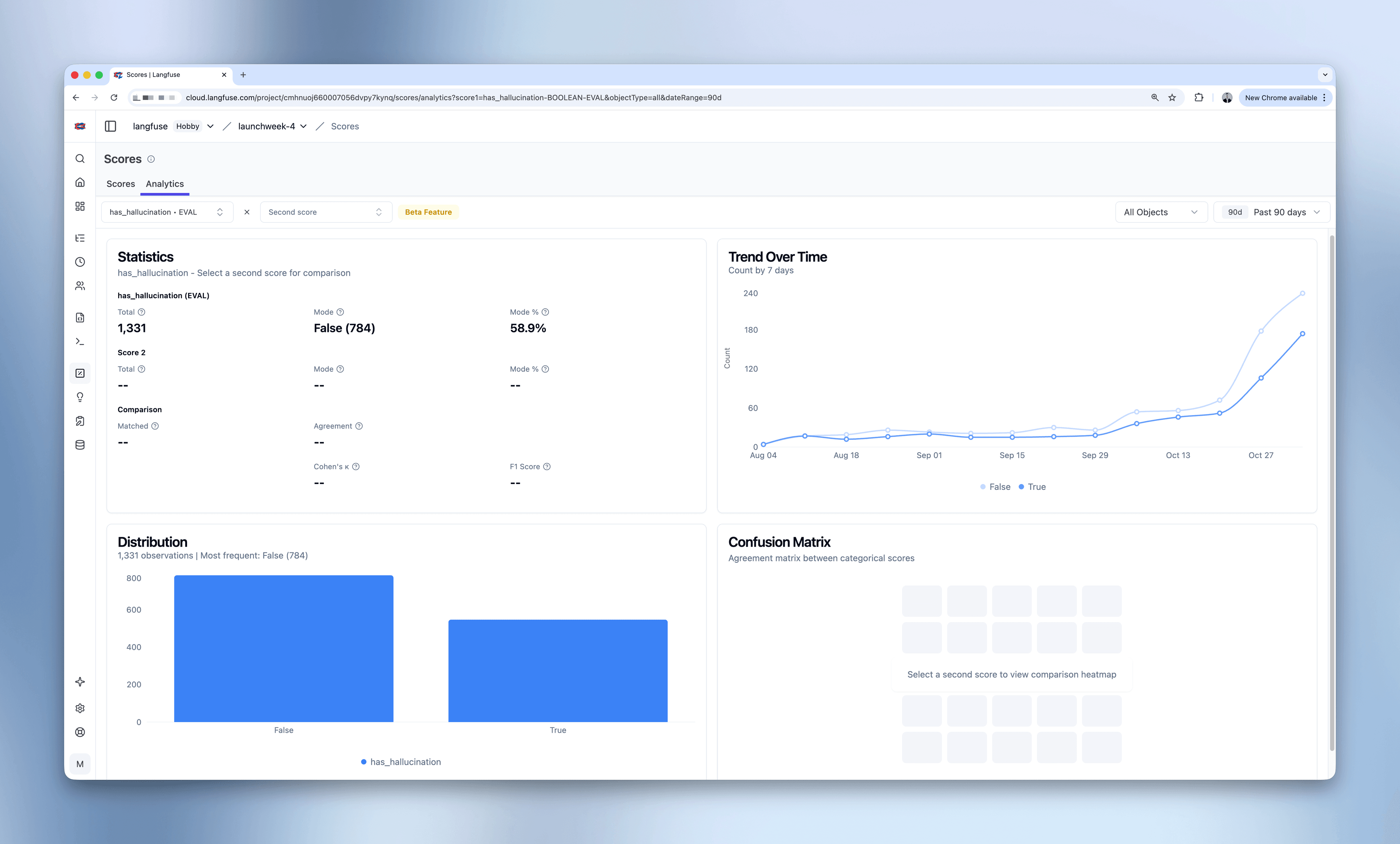
分析单个分数
- 在第一个下拉菜单中选择一个分数
- 选择要分析的对象类型(Traces、Observations、Sessions 或 Dataset Run Items)
- 用日期选择器设置时间范围(例如近 90 天)
- 查看统计卡片中的总数量、均值/众数和标准差
- 浏览分布图表,查看分数值的散布情况
- 检查趋势图,跟踪时间维度上的变化
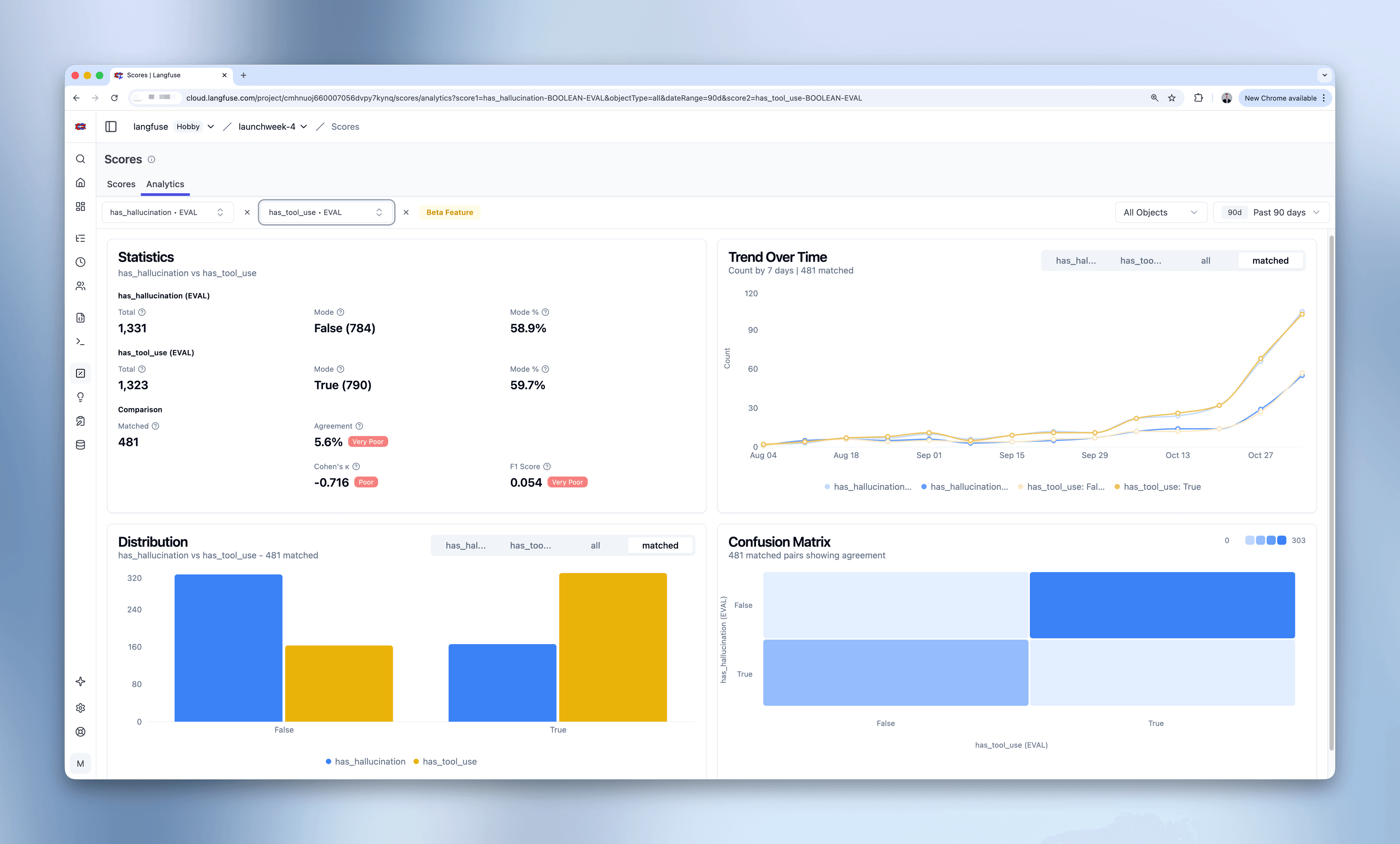
比较两个分数
- 在第二个下拉菜单中选择第二个分数(必须是同一数据类型)
- 查看统计卡片中的对比指标:
- 匹配数量(关联到同一父对象的分数)
- 相关性指标(Pearson、Spearman)
- 误差指标(数值型分数的 MAE、RMSE)
- 一致性指标(分类/布尔型的 Cohen’s Kappa、F1、整体一致率)
- 检查分数比较热力图:
- 强对角线模式表明一致性良好
- 反对角线模式表明负相关
- 散乱模式说明对齐度低
- 在 matched 与 all 标签页中比较分布
- 跟踪两个分数随时间的趋势
关键特性
多种数据类型支持
分数分析会根据分数的数据类型自动调整可视化和指标:
数值型分数(连续值,例如 1-10 的评分)
- 分布:10 个分桶的直方图,展示数值范围
- 比较:10×10 热力图,展示相关性模式
- 指标:Pearson 相关系数、Spearman 相关系数、MAE(平均绝对误差)、RMSE(均方根误差)
分类型分数(离散类别,如 “good/bad/neutral”)
- 分布:每个类别一个柱形的柱状图
- 比较:N×M 混淆矩阵,展示类别如何对齐
- 指标:Cohen’s Kappa、F1 分数、整体一致率
布尔型分数(true/false 二值)
- 分布:两个类别的柱状图
- 比较:2×2 混淆矩阵
- 指标:Cohen’s Kappa、F1 分数、整体一致率
匹配数据 vs 全量数据
分数分析提供两种视图来理解你的数据:
匹配数据(默认标签页)
- 只显示同时拥有所选两个分数的父对象(trace、observation、会话或数据集运行条目)
- 让评估方法之间的比较有效
- 当两个分数指向同一父对象时即视为匹配
- 用此视图衡量一致性和相关性
全量数据(单个分数标签页)
- 独立显示每个分数的完整分布
- 揭示评估覆盖度(多少父对象有该分数)
- 帮助识别评估策略中的空白
时间维度分析
趋势图帮你监控分数模式,包含以下能力:
- 可配置的间隔:从分钟到年(5m、30m、1h、3h、1d、7d、30d、90d、1y)
- 自动选择间隔:根据所选时间范围智能给出默认值
- 空缺补齐:缺失的时间段补 0,可视化更连贯
- 平均值计算:副标题展示该时间段的总体平均
统计指标
分数分析提供业内标准的统计指标,并附带解读说明:
相关性指标(数值型分数)
Pearson 相关系数:衡量两个分数之间的线性关系。取值范围 -1(完全负相关)到 1(完全正相关)。
- 0.9-1.0:非常强相关
- 0.7-0.9:强相关
- 0.5-0.7:中等相关
- 低于 0.5:弱相关
Spearman 相关系数:衡量单调关系(基于秩)。比 Pearson 更稳健,对离群值不敏感。
误差指标(数值型分数)
MAE(平均绝对误差):分数差的绝对值的平均,越低越好。
RMSE(均方根误差):差值平方平均后再开方,比 MAE 对较大误差惩罚更重。
一致性指标(分类/布尔型分数)
Cohen’s Kappa:考虑随机一致性后的一致性度量。取值范围 -1 到 1。
- 0.81-1.0:几乎完全一致
- 0.61-0.80:高度一致
- 0.41-0.60:中等一致
- 低于 0.41:一般到弱一致
F1 分数:精确率和召回率的调和平均,取值范围 0 到 1,1 为完美。
整体一致率:分类一致样本所占的简单百分比,未对随机一致进行调整。
示例用例
验证 LLM judge 可靠性
场景:你同时使用 GPT-4 和 Gemini 评估有用性。它们的结果是否一致?
工作流:
- 选择 “helpfulness_gpt4-NUMERIC-EVAL” 作为分数 1
- 选择 “helpfulness_gemini-NUMERIC-EVAL” 作为分数 2
- 查看统计卡片:Pearson 相关系数 0.984,标记为 “Very Strong”
- 检查热力图:强对角线模式确认对齐
- 结果:两个 judge 高度一致,你的评估是可靠的
人工与 AI 标注一致性
场景:你有人工标注和 AI 评估两套质量分数,能否信任 AI?
工作流:
- 选择 “quality-CATEGORICAL-ANNOTATION” 作为分数 1
- 选择 “quality-CATEGORICAL-EVAL” 作为分数 2
- 查看混淆矩阵:强对角线说明一致性良好
- 查看 Cohen’s Kappa:0.85 表示 “几乎完全一致”
- 结果:AI 评估与人工判断对齐良好
识别负相关
场景:理解应用中不同行为之间的关系
工作流:
- 选择 “has_tool_use-BOOLEAN-EVAL” 作为分数 1
- 选择 “has_hallucination-BOOLEAN-EVAL” 作为分数 2
- 观察混淆矩阵:反对角线模式
- 结果:当你的 agent 使用工具时,幻觉发生频率更低
跟踪评估覆盖度
场景:你的评估数据完整度如何?
工作流:
- 选择任意一个分数
- 在分布中比较 “all” 标签页与 “matched” 标签页
- 查看总数:1,143 个分数 1 的样本 vs 567 对匹配的样本
- 结果:识别出大约 50% 的父对象同时拥有两个分数
检测质量回归
场景:最近一次部署后模型质量是否下降?
工作流:
- 选择一个质量或性能分数
- 把时间范围设置为覆盖部署前后两段时期
- 查看趋势图中是否出现下滑或变化
- 结果:快速发现质量回归并定位根因
当前限制
Beta 功能:分数分析当前处于 Beta 阶段,欢迎反馈问题与建议。
当前约束:
- 最多两个分数:当前一次最多比较两个分数。多向比较请用两两分析的方式完成。
- 仅同类型可比:只能在相同数据类型的分数之间比较(数值型对数值型、分类型对分类型、布尔型对布尔型)。
- 采样:为优化性能,预期返回 >100k 分数(任一侧)的查询会自动应用随机采样。这种采样近似真随机采样,能保持数据的统计性质。在采样生效时会有可见提示,如果你需要完整数据集,可以通过时间范围或对象类型筛选缩小分析范围。
技巧与最佳实践
选择要比较的分数
- 只能比较同一数据类型的分数
- 不同量纲的分数也可以比较,但误差指标(MAE、RMSE)会受量纲差异影响
- 选择评估相似维度的分数才会得到有意义的对比
解读热力图
- 对角线模式:表示一致(两个分数赋予相近的值)
- 反对角线模式:表示负相关(一个分数高,另一个对应低)
- 散乱模式:表示低相关或数据噪声大
- 格子深浅:颜色越深,落在该格子的样本越多
理解匹配数据
- 每个分数总是关联到一个父对象(trace、observation、会话或数据集运行条目)
- 当两个分数指向同一父对象时,它们就构成一对匹配
- 如果匹配数远小于各自总数,说明覆盖存在空白
- 某些评估方法可能是有选择性的(例如只标注边界情况)
相关资源
- 构建自定义仪表盘,把分数趋势与其他指标一起可视化。
- 如需以编程方式查询聚合分数数据用于外部监控,请使用 Metrics API。