通过 UI 运行实验(prompt 实验)
你可以在 Litefuse UI 中运行通过 UI 触发的实验(也称 prompt 实验),用提示词管理中的不同 prompt 版本或不同模型进行测试,并并排比较结果。
可选地,你可以使用 LLM-as-a-Judge 评估器基于期望输出自动给回复打分,并在聚合层面进一步分析结果。
为什么使用 prompt 实验?
- 快速测试不同的 prompt 版本或模型
- 借助数据集结构化地测试不同 prompt 版本和模型
- 通过 prompt 实验快速迭代 prompt
- 可选地用 LLM-as-a-Judge 评估器基于数据集中的期望输出给回复打分
- 在修改 prompt 时通过自动测试避免回归
实验始终在实验运行时的最新数据集版本上执行。对特定数据集版本运行实验的支持很快会上线。
前置条件
创建一个可用的 prompt
创建你想要测试和评估的 prompt。如何创建 prompt?
**prompt 可用的标准:**你的 prompt 中变量与将要在数据集运行中使用的数据集条目 key 相匹配。见下方示例。
示例:prompt 变量与数据集条目 key 的映射
Prompt:
{{ documentation }}
Question: {{question}}
数据集条目:
{
"documentation": "Litefuse is an AI agent observability and evaluation platform",
"question": "What is Litefuse?"
}在该示例中:
- prompt 变量
{{documentation}}映射到 JSON key"documentation" - prompt 变量
{{question}}映射到 JSON key"question" - 这两个 key 都必须存在于数据集条目的 input JSON 中,实验才能成功运行
示例:聊天消息占位符映射
除了变量,你还可以将聊天消息 prompt 中的占位符映射到数据集条目的 key。 当数据集条目中也包含例如要使用的聊天消息历史时,这非常有用。 你的聊天 prompt 需要包含一个带名称的占位符。占位符内的变量不会被解析。
聊天 Prompt:
占位符名称:message_history
数据集条目:
{
"message_history": [
{
"role": "user",
"content": "What is Litefuse?"
},
{
"role": "assistant",
"content": "Litefuse is a tool for tracking and analyzing the performance of language models."
}
],
"question": "What is Litefuse?"
}在该示例中:
- 聊天 prompt 占位符
message_history映射到 JSON key"message_history"。 - prompt 变量
{{question}}映射到 JSON key"question",且不在某个占位符消息内部。 - 这两个 key 都必须存在于数据集条目的 input JSON 中,实验才能成功运行
创建一个可用的数据集
创建一个包含 prompt 实验所需输入和期望输出的数据集。如何创建数据集?
数据集可用的标准:[1] 数据集条目以 JSON 对象作为 input,且 [2] 这些对象的 JSON key 与你将要使用的 prompt 中的变量匹配。见下方示例。
示例:prompt 变量与数据集条目 key 的映射
Prompt:
{{ documentation }}
Question: {{question}}
数据集条目:
{
"documentation": "Litefuse is an AI agent observability and evaluation platform",
"question": "What is Litefuse?"
}在该示例中:
- prompt 变量
{{documentation}}映射到 JSON key"documentation" - prompt 变量
{{question}}映射到 JSON key"question" - 这两个 key 都必须存在于数据集条目的 input JSON 中,实验才能成功运行
配置 LLM 连接
由于你的 prompt 会针对每个数据集条目执行,你需要在项目设置中配置一个 LLM 连接。如何配置 LLM 连接?
可选:设置 LLM-as-a-judge
你可以设置一个 LLM-as-a-judge 评估器,基于期望输出对回复打分。请将 LLM-as-a-Judge 的目标设置为 “Experiment runs”,并按照你要使用的数据集进行筛选。如何设置 LLM-as-a-judge?
通过 UI 触发实验(prompt 实验)
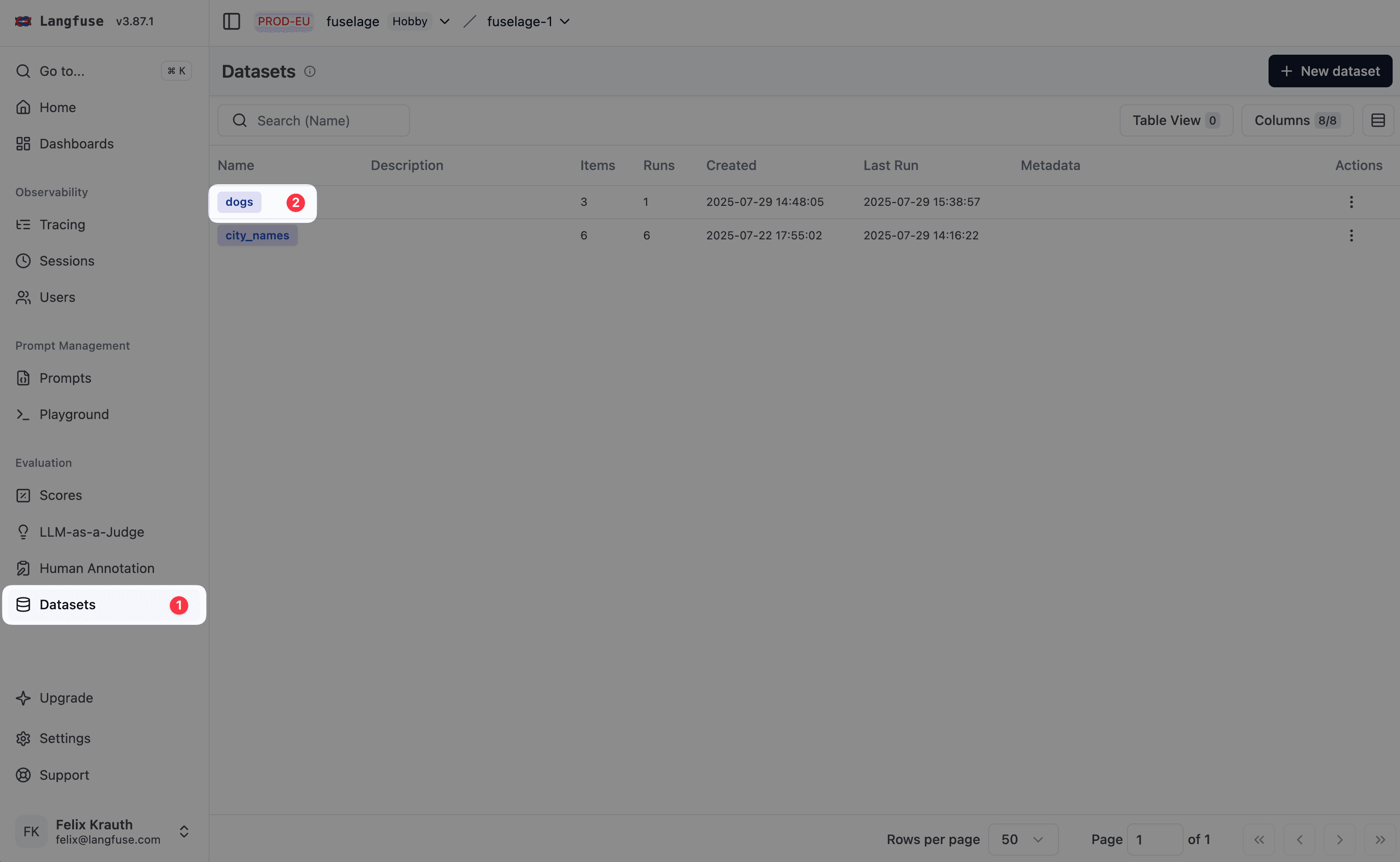
进入数据集
数据集运行目前从数据集详情页发起。
- 进入
Your Project>Datasets - 点击你想发起数据集运行的数据集
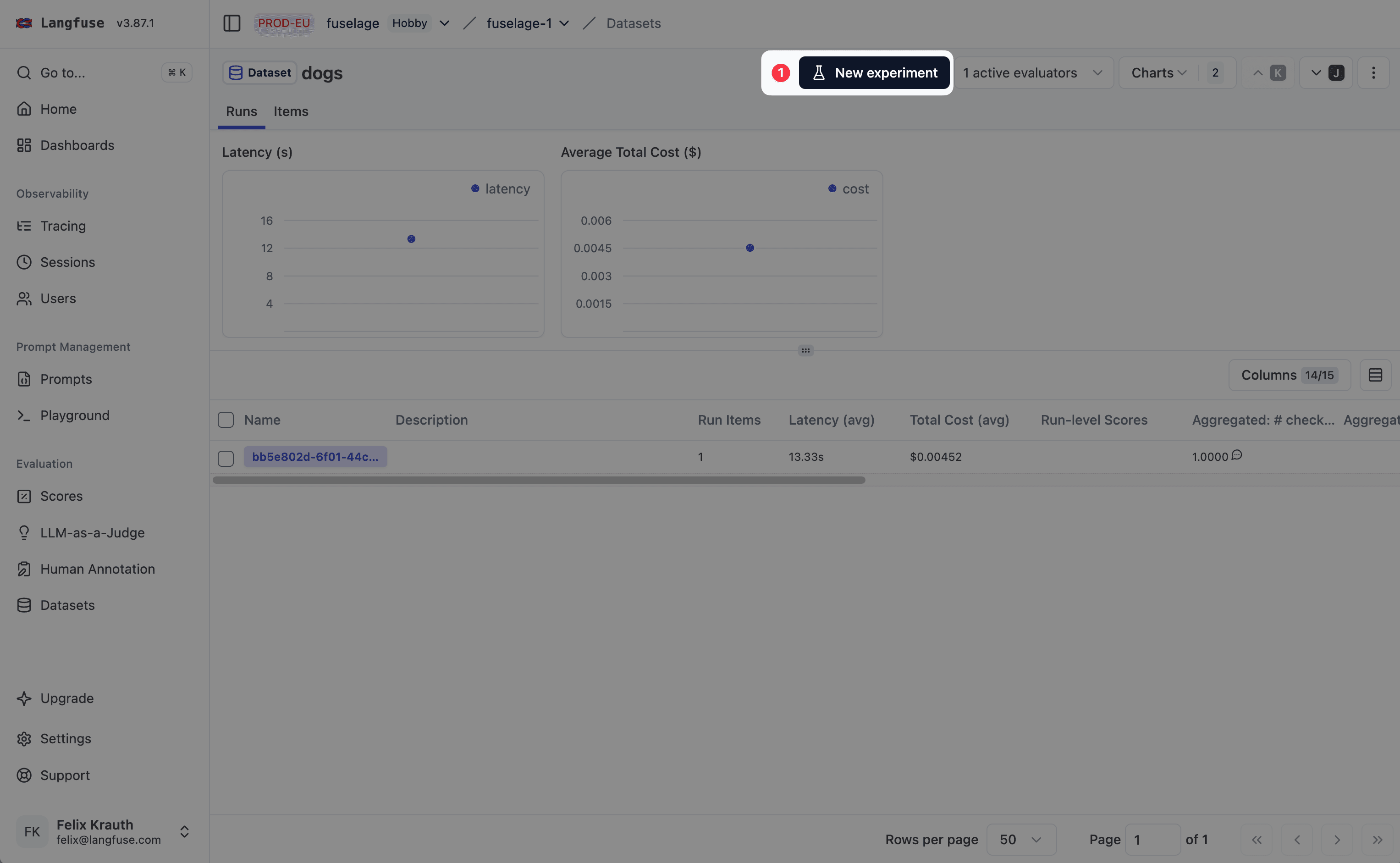
打开设置页面
点击 Start Experiment 打开设置页面
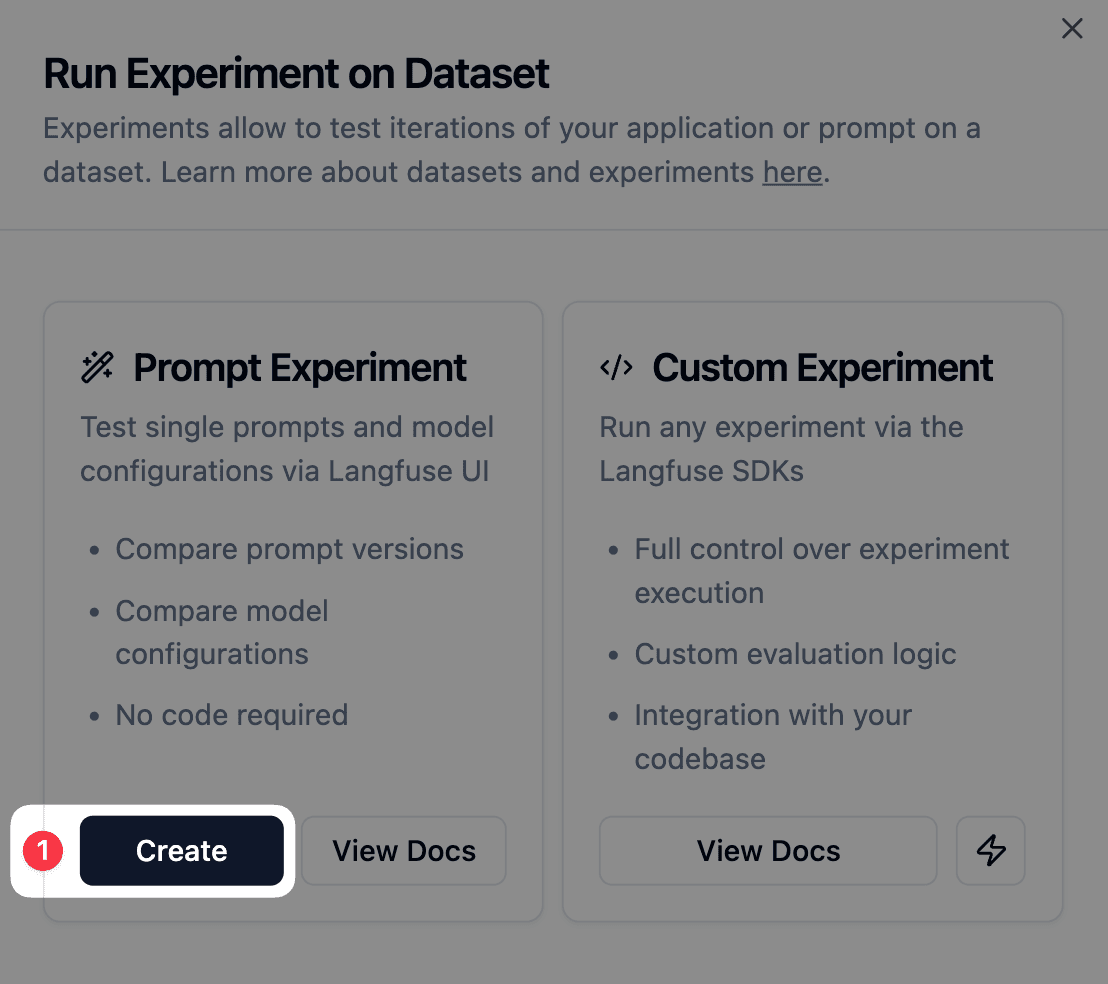
点击 prompt Experiment 下方的 Create
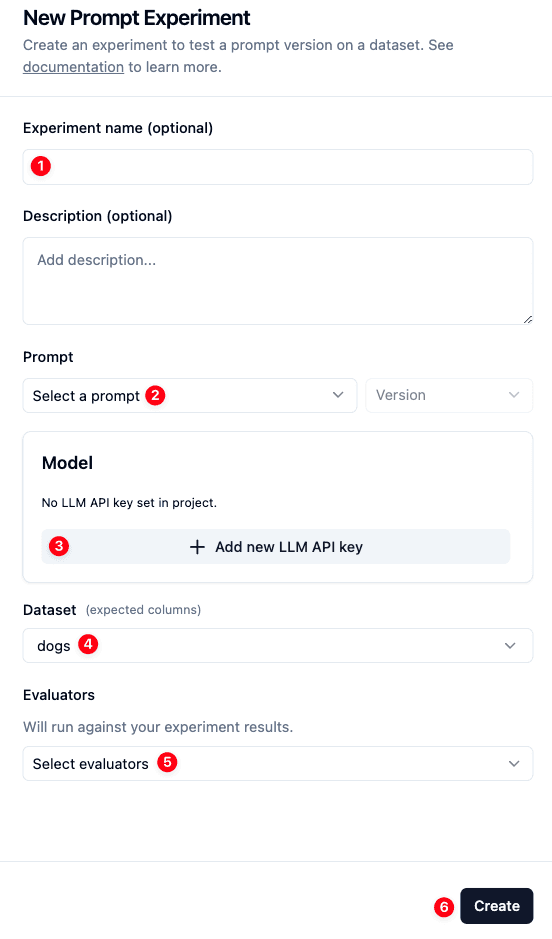
配置数据集运行
- 设置数据集运行名称
- 选择你想使用的 prompt
- 如果只有一处动态内容,我们建议使用一个含静态 system prompt 和动态 user message(例如以完整 user message 作为变量)的 chat prompt。这样能把动态内容映射为 user message。
- 如果有多处动态内容,我们建议在 prompt 中为每处动态内容创建一个变量,确保你能把它们一一映射。
- 设置或选择你想使用的 LLM 连接
- 选择你想使用的数据集
- 可选:配置结构化输出 —— 打开开关以强制使用 JSON schema 响应格式
- 选择项目中已有的 schema 或新建一个
- schema 可以在 Playground 中创建并保存,然后在此处复用
- 通过 schema 选择器旁的眼睛图标查看/编辑 schema
- 可选:选择你想使用的评估器
- 点击
Create触发数据集运行
结构化输出确保 LLM 回复符合特定的 JSON schema。当你需要一致的、可解析的输出来做评估或下游处理时,这非常有用。在 Playground 中定义的同一批 schema 也可在实验中使用。
这会触发数据集运行,你会被跳转到数据集运行页面。运行可能需要几秒到几分钟,取决于 prompt 复杂度和数据集规模。
比较运行
每次实验运行完成后,你可以在数据集运行表中查看聚合分数,并并排比较结果。
相关资源
- 如果你需要评估完整的应用或 agent 逻辑(包括自定义运行时配置),而不是只测试 prompt,请使用 Experiments via SDK。你也可以通过 webhook 在 UI 中触发基于 SDK 的评估运行。