数据集
数据集是一组输入和期望输出的集合,用于测试你的应用。无论是基于 UI 还是基于 SDK 的实验都支持 Litefuse 数据集。
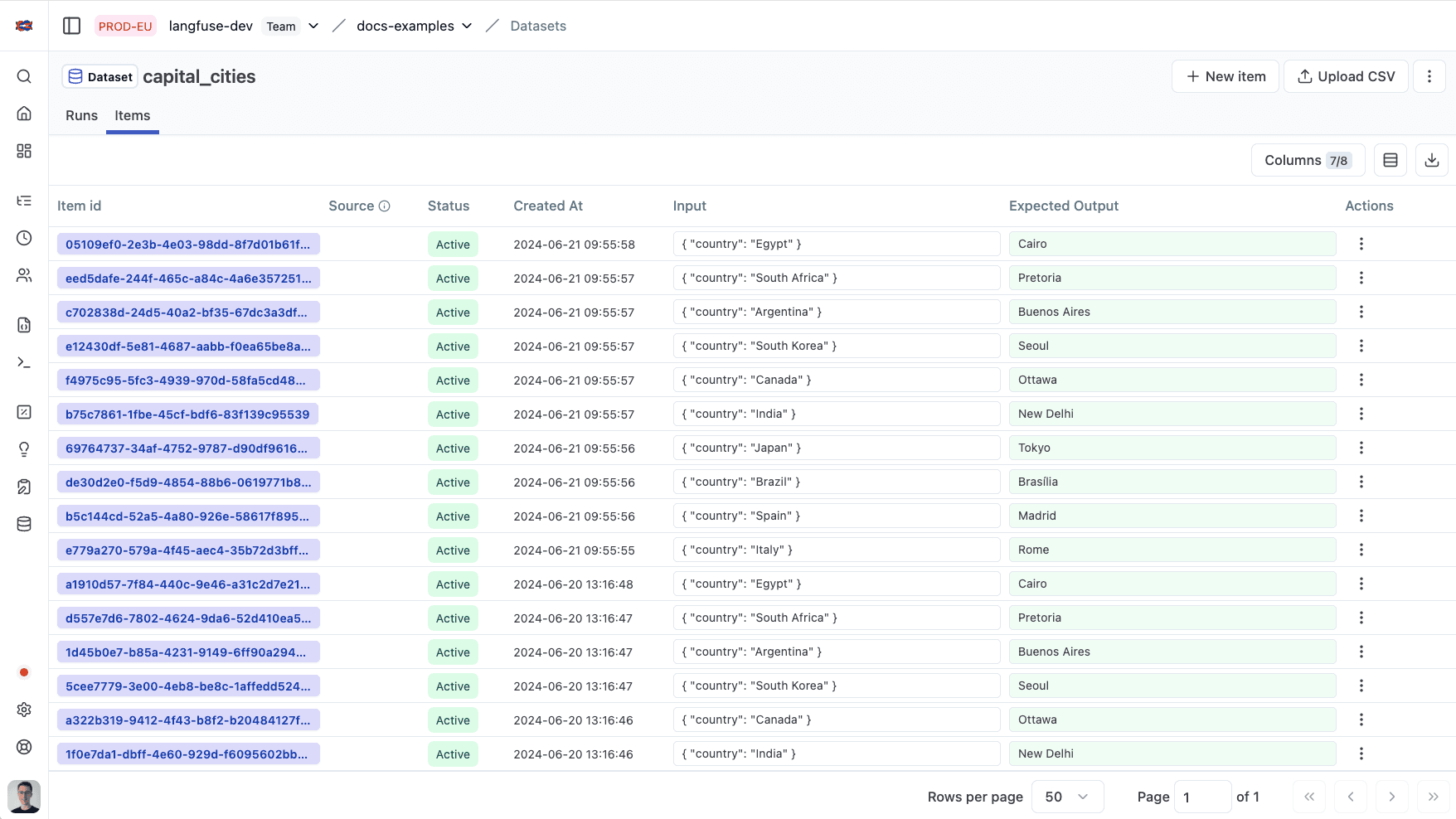
Litefuse 数据集视图
为什么使用数据集?
- 用真实的生产 trace 为你的应用创建测试用例
- 与团队协作创建和收集数据集条目
- 让测试数据有一个唯一的来源
快速开始
创建一个数据集
数据集名称在项目内唯一。
langfuse.create_dataset(
name="<dataset_name>",
# optional description
description="My first dataset",
# optional metadata
metadata={
"author": "Alice",
"date": "2022-01-01",
"type": "benchmark"
}
)See Python SDK docs for details on how to initialize the Python client.
上传或新建数据集条目
数据集条目可以通过提供输入(以及可选的期望输出)添加到数据集中。如果你愿意,也可以通过 Litefuse UI 中的 CSV 上传器导入数据集条目。
langfuse.create_dataset_item(
dataset_name="<dataset_name>",
# any python object or value, optional
input={
"text": "hello world"
},
# any python object or value, optional
expected_output={
"text": "hello world"
},
# metadata, optional
metadata={
"model": "llama3",
}
)See Python SDK docs for details on how to initialize the Python client.
数据集文件夹
数据集可以组织到虚拟文件夹中,用于将用途相似的数据集分组。
要创建文件夹,在数据集名称中加入斜杠(/)。UI 会自动把每一段以 / 结尾的部分识别为文件夹。
在文件夹中创建和获取数据集
通过在数据集名称中加入斜杠(/),可以使用 Litefuse UI 或 SDK 在文件夹中创建并获取数据集。
dataset_name = "evaluation/qa-dataset"
# When creating a dataset, use the full dataset name
langfuse.create_dataset(
name=dataset_name,
)
# When fetching a dataset in a folder, use the full dataset name
langfuse.get_dataset(
name=dataset_name
)
这会在名为 evaluation 的文件夹中创建并获取一个名为 qa-dataset 的数据集。完整的数据集名称仍然是 evaluation/qa-dataset。
URL 编码:通过 API 或 JS/TS SDK 把带斜杠的数据集名作为路径参数使用时,请进行 URL 编码。例如在 TypeScript 中:encodeURIComponent(name)。
版本
要在 Litefuse UI 中访问数据集版本,进入:Datasets > 进入某个数据集 > 选择 Items 标签页。在该页面你可以切换版本视图。
每次对数据集条目执行 add、update、delete 或 archive 都会产生一个新的数据集版本。版本通过 timestamp 跟踪随时间发生的变化。
GET API 默认返回查询时刻的最新版本。你可以通过 version 参数获取指定版本时间戳的数据集。
版本仅适用于数据集条目,不包括数据集 schema。数据集 schema 的变更不会产生新版本。
获取指定版本的数据集
你可以通过提供版本时间戳来获取数据集在某个时间点的状态。这会只返回该时间戳存在的条目。
from langfuse import get_client
from datetime import datetime, timedelta
langfuse = get_client()
# Capture dataset state as of 2025-12-15 at 06:30:00 UTC
version_timestamp = datetime(2025, 12, 15, 6, 30, 0, tzinfo=timezone.utc)
# Fetch dataset at version timestamp
dataset_at_version = langfuse.get_dataset(
name="my-dataset",
version=version_timestamp
)
# Fetch latest version
dataset_latest = langfuse.get_dataset(name="my-dataset")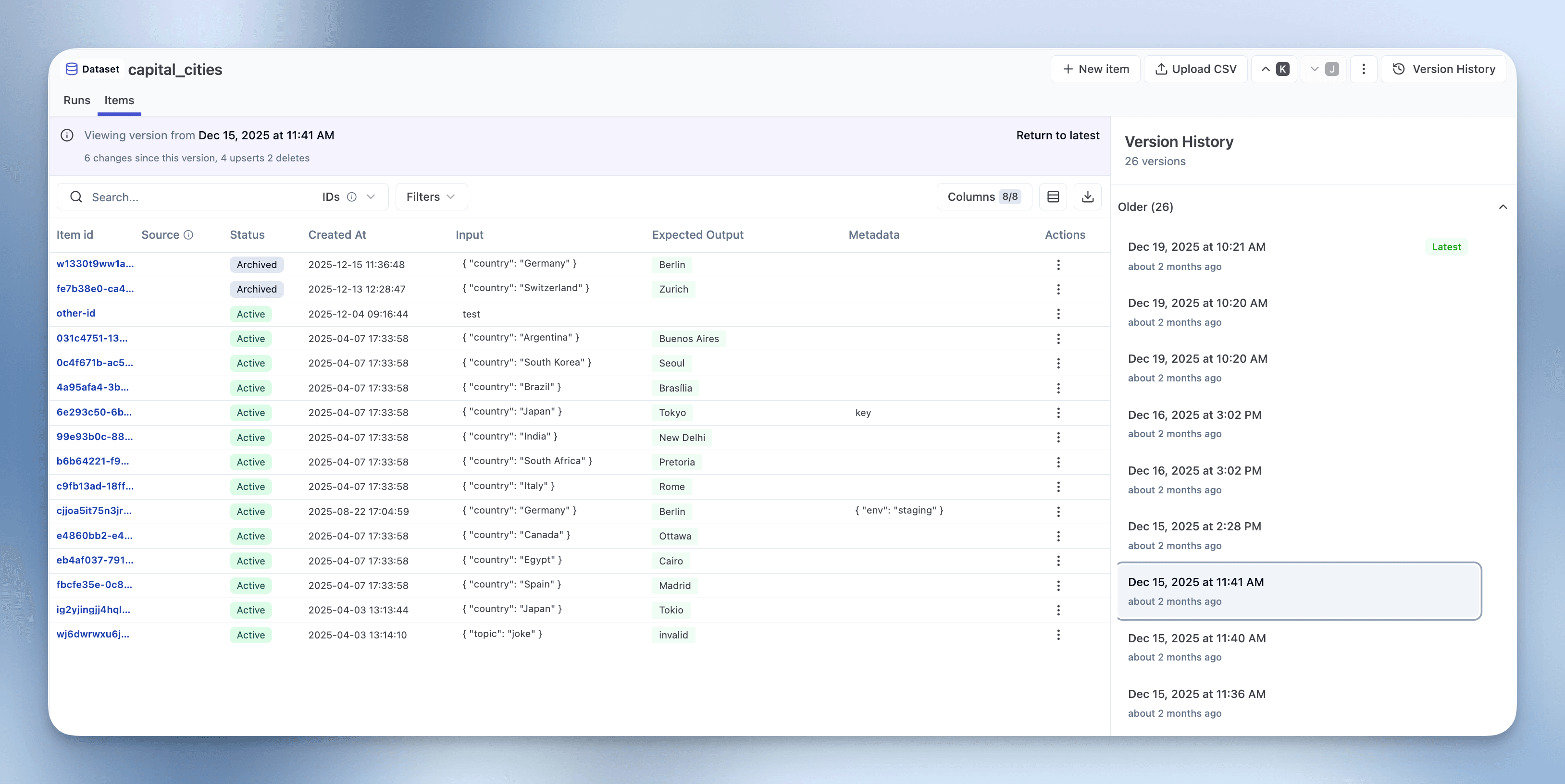
在版本化数据集上运行实验
你可以直接在版本化的数据集上运行实验。这适用于比较模型在不同数据集版本下的表现,或基于某个时间点的精确数据集状态复现实验结果。
from datetime import timedelta
import time
from langfuse import Langfuse
langfuse = Langfuse()
version_timestamp = datetime(2025, 12, 15, 6, 30, 0, tzinfo=timezone.utc)
# Fetch versioned dataset
versioned_dataset = langfuse.get_dataset("qa-dataset", version=version_timestamp)
# Run experiment on the versioned dataset
def my_llm_application(*, item, **kwargs):
# Your LLM application logic here
# For this example, we'll just return the expected output
return item.expected_output
result = versioned_dataset.run_experiment(
name="Baseline Experiment v1",
description="Running on dataset v1",
task=my_llm_application
)这种方式通过以下能力来确保可复现性:
- 即使条目已被更新或删除,仍可在历史数据集版本上重新运行实验
- 比较数据集变更前后的模型表现
- 保持实验一致性,并精确复现先前运行的结果
- 在同一基线数据集版本上测试改进
Schema 强校验
可以为数据集添加 JSON Schema 校验,确保所有数据集条目符合既定结构。这有助于保持数据质量、尽早发现错误并在团队间保持一致性。
创建或更新数据集时,你可以为 input 和/或 expectedOutput 字段定义 JSON schema。一旦设置,所有数据集条目会被自动按这些 schema 校验。合法条目会被接受,不合法条目会被拒绝并附带详细的校验错误信息。
langfuse.create_dataset(
name="qa-conversations",
input_schema={
"type": "object",
"properties": {
"messages": {
"type": "array",
"items": {
"type": "object",
"properties": {
"role": {"type": "string", "enum": ["user", "assistant", "system"]},
"content": {"type": "string"}
},
"required": ["role", "content"]
}
}
},
"required": ["messages"]
},
expected_output_schema={
"type": "object",
"properties": {"response": {"type": "string"}},
"required": ["response"]
}
)创建合成数据集
通常你会想生成一些合成示例来测试应用、为数据集打底。LLM 非常擅长通过 prompt 生成常见问题/任务。
下面这本 cookbook 中给出了如何生成合成数据集的示例:
从生产数据创建条目
一种常见工作流是:从生产 trace 中挑选应用表现不佳的样例,让专家给出期望输出,再用同样的数据测试新版本的应用。
langfuse.create_dataset_item(
dataset_name="<dataset_name>",
input={ "text": "hello world" },
expected_output={ "text": "hello world" },
# link to a trace
source_trace_id="<trace_id>",
# optional: link to a specific span, event, or generation
source_observation_id="<observation_id>"
)批量将 observation 添加到数据集
你可以在 observations 表中批量将多个 observation 添加到数据集。这非常适合从生产数据快速构建测试数据集。
字段映射系统让你能掌控如何把 observation 数据转换为数据集条目。你可以原样使用整个字段(例如把完整的 observation input 映射成数据集条目的 input),或使用 JSON path 表达式提取特定值,或者从多个字段构建自定义对象。
- 进入 Observations 表
- 用筛选条件找到相关的 observation
- 通过复选框选择 observation
- 点击 Actions → Add to dataset
- 选择创建新数据集或选择已有数据集
- 配置字段映射,控制 observation 数据如何映射到数据集条目字段
- 预览映射并确认
批量操作在后台运行,并支持部分成功。如果部分 observation 没能通过数据集 schema 的校验,合法条目仍会被添加,错误会被记录便于回查。你可以在 Settings → Batch Actions 查看进度。
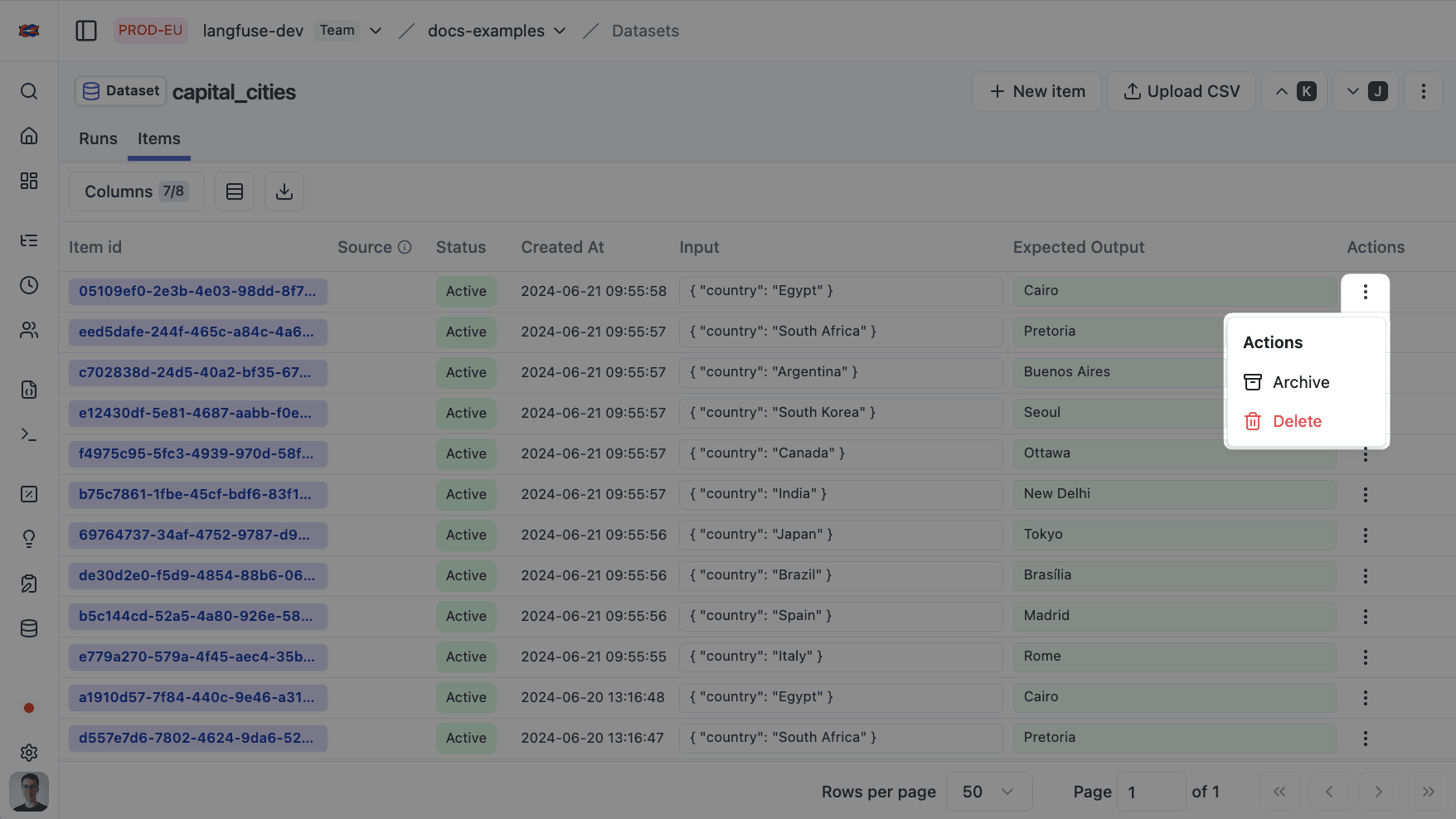
编辑/归档数据集条目
你可以编辑或归档数据集条目。归档的条目会从未来的实验运行中移除。
通过提供你想更新的条目 id,可以对条目执行 upsert。
langfuse.create_dataset_item(
id="<item_id>",
# example: update status to "ARCHIVED"
status="ARCHIVED"
)
数据集运行
创建好数据集后,你就可以基于它来测试和评估你的应用。
了解更多关于实验数据模型的内容。