模型用量与成本追踪
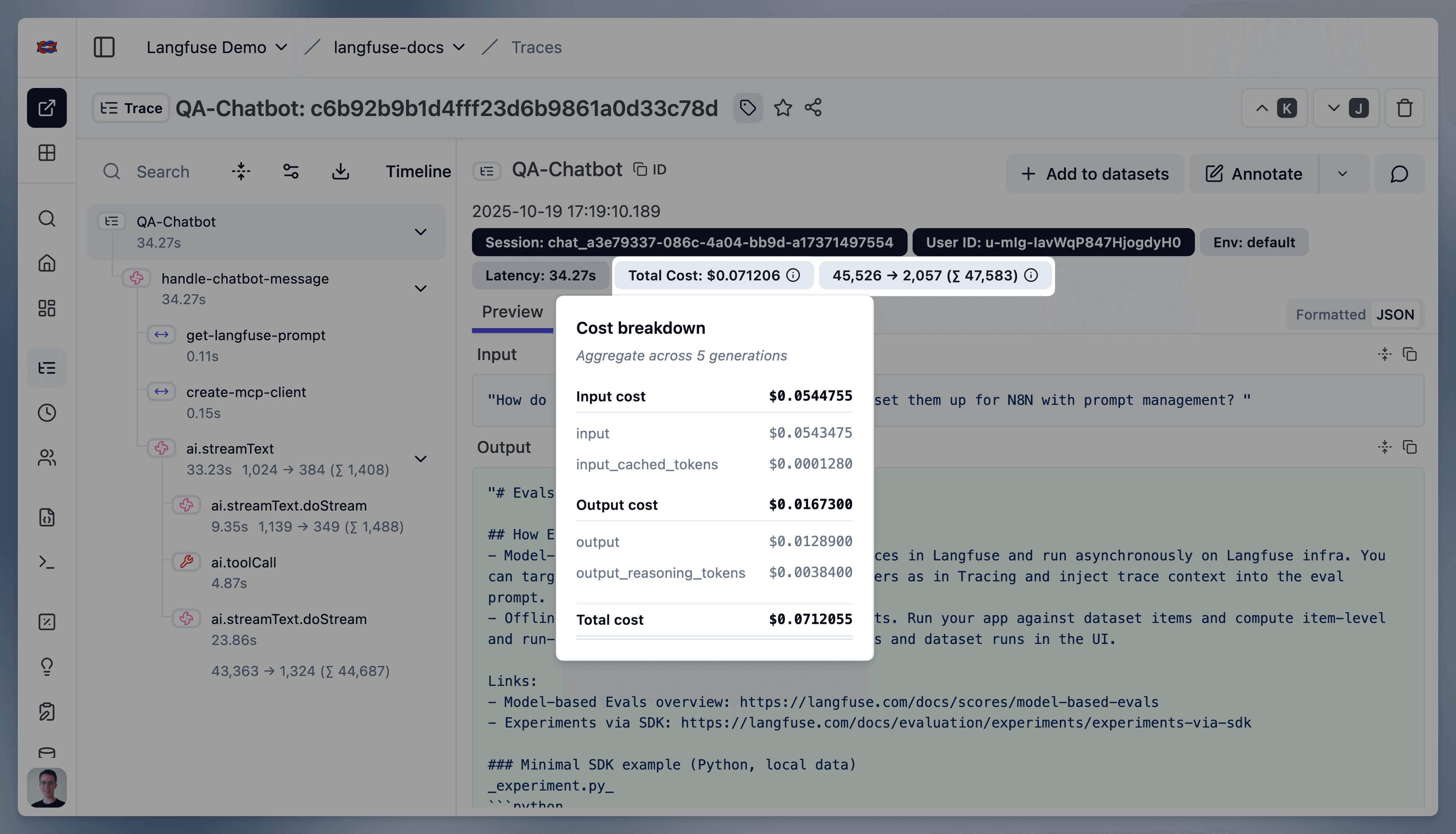
Litefuse 追踪 LLM generation 的用量和成本,并按用量类型进行拆分。用量和成本可以在 类型 为 generation 和 embedding 的 observation 上追踪。
- 用量明细(usage details):每种用量类型消耗的单元数量
- 成本明细(cost details):每种用量类型对应的美元成本
用量类型可以是任意字符串,因 LLM 提供方不同而不同。最高层次上可以简单划分为 input 和 output。随着 LLM 越来越复杂,还需要更多用量类型,例如 cached_tokens、audio_tokens、image_tokens。
在 UI 中,Litefuse 会将所有包含字符串 input 的用量类型汇总为输入用量类型,同样地,包含 output 的视为输出用量类型。如果没有上报 total 用量类型,Litefuse 会把所有用量类型的单元数加总作为 total。
用量明细和成本明细既可以
- 通过 API、SDK 或集成上报
- 也可以基于 generation 的
model参数推断。Litefuse 内置了一份主流模型及其分词器的列表,包括 OpenAI、Anthropic 和 Google 模型。你也可以添加自己的自定义模型定义,或在 GitHub 上请求官方支持新模型。推断成本会在写入时使用当时可用的模型与价格信息计算。
上报的用量和成本优先于推断的用量和成本:
通过 Metrics API,你可以从 Litefuse 检索聚合后的用量和成本指标,用于下游的分析、计费和限流。该 API 支持按应用类型、用户或标签过滤。
上报用量和/或成本
如果 LLM 响应中提供了用量和/或成本,那么直接上报是 Litefuse 中最准确、最稳健的追踪方式。
很多 Litefuse 集成会自动从 LLM 响应中捕获用量明细和成本明细数据。如果效果不符合预期,请在 GitHub 上提一个 issue。
使用 @observe() 装饰器时:
from langfuse import observe, get_client
import anthropic
langfuse = get_client()
anthropic_client = anthropic.Anthropic()
@observe(as_type="generation")
def anthropic_completion(**kwargs):
# optional, extract some fields from kwargs
kwargs_clone = kwargs.copy()
input = kwargs_clone.pop('messages', None)
model = kwargs_clone.pop('model', None)
langfuse.update_current_generation(
input=input,
model=model,
metadata=kwargs_clone
)
response = anthropic_client.messages.create(**kwargs)
langfuse.update_current_generation(
usage_details={
"input": response.usage.input_tokens,
"output": response.usage.output_tokens,
"cache_read_input_tokens": response.usage.cache_read_input_tokens
# "total": int, # if not set, it is derived from input + cache_read_input_tokens + output
},
# Optionally, also ingest usd cost. Alternatively, you can infer it via a model definition in Langfuse.
cost_details={
# Here we assume the input and output cost are 1 USD each and half the price for cached tokens.
"input": 1,
"cache_read_input_tokens": 0.5,
"output": 1,
# "total": float, # if not set, it is derived from input + cache_read_input_tokens + output
}
)
# return result
return response.content[0].text
@observe()
def main():
return anthropic_completion(
model="claude-3-opus-20240229",
max_tokens=1024,
messages=[
{"role": "user", "content": "Hello, Claude"}
]
)
main()手动创建 generation 时:
from langfuse import get_client
import anthropic
langfuse = get_client()
anthropic_client = anthropic.Anthropic()
with langfuse.start_as_current_observation(
as_type="generation",
name="anthropic-completion",
model="claude-3-opus-20240229",
input=[{"role": "user", "content": "Hello, Claude"}]
) as generation:
response = anthropic_client.messages.create(
model="claude-3-opus-20240229",
max_tokens=1024,
messages=[{"role": "user", "content": "Hello, Claude"}]
)
generation.update(
output=response.content[0].text,
usage_details={
"input": response.usage.input_tokens,
"output": response.usage.output_tokens,
"cache_read_input_tokens": response.usage.cache_read_input_tokens
# "total": int, # if not set, it is derived from input + cache_read_input_tokens + output
},
# Optionally, also ingest usd cost. Alternatively, you can infer it via a model definition in Langfuse.
cost_details={
# Here we assume the input and output cost are 1 USD each and half the price for cached tokens.
"input": 1,
"cache_read_input_tokens": 0.5,
"output": 1,
# "total": float, # if not set, it is derived from input + cache_read_input_tokens + output
}
)与 OpenAI 的兼容性
为了更好地兼容 OpenAI,你也可以使用 OpenAI 的 Usage schema。prompt_tokens 会被映射为 input,completion_tokens 会被映射为 output,total_tokens 会被映射为 total。prompt_tokens_details 内嵌的字段会以 input_ 前缀展平,completion_tokens_details 内嵌的字段会以 output_ 前缀展平。
from langfuse import get_client
langfuse = get_client()
with langfuse.start_as_current_observation(
as_type="generation",
name="openai-style-generation",
model="gpt-4o"
) as generation:
# Simulate LLM call
# response = openai_client.chat.completions.create(...)
generation.update(
usage_details={
# usage (OpenAI-style schema)
"prompt_tokens": 10,
"completion_tokens": 25,
"total_tokens": 35,
"prompt_tokens_details": {
"cached_tokens": 5,
"audio_tokens": 2,
},
"completion_tokens_details": {
"reasoning_tokens": 15,
},
}
)你也可以通过 generation.update() 和 generation.end() 上报 OpenAI 风格的 usage。
推断用量和/或成本
如果用量或成本未上报,Litefuse 会在写入时尝试根据 generation 的 model 参数推断缺失的值。这对一些不在响应中包含 usage 或成本的模型提供方或自托管模型尤其有用。
Litefuse 内置了一份主流模型及其分词器的预定义列表,包含 OpenAI、Anthropic、Google。完整列表可以查看这里(需要登录)。
你也可以添加自己的自定义模型定义(参见下文)或在 GitHub 上请求官方支持新模型。
用量
如果模型指定了分词器,Litefuse 会自动为上报的 generation 计算 token 数量。
当前支持的分词器如下:
| 模型 | 分词器 | 使用的 package | 备注 |
|---|---|---|---|
gpt-4o | o200k_base | tiktoken | |
gpt* | cl100k_base | tiktoken | |
claude* | claude | @anthropic-ai/tokenizer | 根据 Anthropic 说法,他们的分词器对于 Claude 3 模型并不准确。如果可能,请使用其 API 响应中返回的 token 数。 |
成本
模型定义中包含每种用量类型的价格。用量类型必须与 generation 的 usage_details 对象中的键完全匹配。
如果(1)上报或推断出了用量,且(2)匹配到的模型定义中含有价格,Litefuse 会在写入时自动为该 generation 计算成本。
价格分层
部分模型提供方会根据所用的输入 token 数量收取不同费率。例如 Anthropic 的 Claude Sonnet 4.5 和 Google 的 Gemini 2.5 Pro,在使用超过 200K 输入 token 时会采用更高的价格。
Litefuse 支持模型的价格分层,使这些与上下文相关的定价结构能够准确计算成本。
分层匹配的工作方式
每个模型可以有多个价格层级,每个层级包含:
- Name:描述性名称(例如 “Standard”、“Large Context”)
- Priority:评估顺序(0 保留给默认层级)
- Conditions:决定该层级何时生效的规则
- Prices:该层级下每种用量类型的成本
在计算成本时,Litefuse 会按优先级顺序评估各个层级(不包含默认层级),第一个条件被满足的层级会被使用。如果没有任何条件层级匹配,则使用默认层级。
条件格式:
usageDetailPattern:用于匹配用量明细键的正则表达式(例如input可以匹配input_tokens、input_cached_tokens等)operator:比较运算符(gt、gte、lt、lte、eq、neq)value:用于比较的阈值caseSensitive:模式匹配是否区分大小写(默认值:false)
例如,Claude Sonnet 4.5 的 “Large Context” 层级条件为:input > 200000,意味着当所有匹配 “input” 模式的用量明细之和超过 200,000 token 时该层级生效。
自定义模型定义
你可以灵活地向 Litefuse 添加自己的模型定义(包括价格分层)。这对那些未包含在 Litefuse 维护列表中的自托管或微调模型尤其有用。
要在 Litefuse UI 中添加自定义模型定义,你可以点击模型名称旁的 ”+” 号,或前往 Project Settings > Models 添加新的模型定义。
然后填入每种 token 类型的价格并保存模型定义。这样所有使用该模型的新 trace 都会得到正确的 token 用量和成本推断。
模型按以下规则匹配到 generation:
| Generation 属性 | 模型属性 | 备注 |
|---|---|---|
model | match_pattern | 使用正则表达式,例如 (?i)^(gpt-4-0125-preview)$ 可匹配 gpt-4-0125-preview。 |
用户自定义模型的优先级高于 Litefuse 维护的模型。
更多说明
使用 openai 分词器时,需要指定如下分词配置。你也可以从预定义 OpenAI 模型列表中复制配置。详情参见 OpenAI 文档。tokensPerName 和 tokensPerMessage 对 chat 模型是必填项。
{
"tokenizerModel": "gpt-3.5-turbo", // tiktoken model name
"tokensPerName": -1, // OpenAI Chatmessage tokenization config
"tokensPerMessage": 4 // OpenAI Chatmessage tokenization config
}推理模型的成本推断
对于 OpenAI o1 系列等推理模型,无法通过对 LLM 输入和输出进行分词来推断成本。也就是说,如果没有上报 token 数量,Litefuse 无法为推理模型推断成本。
推理模型在产生最终响应前会经过多个步骤。每一步都会生成被计入输出 token 的推理 token。因此实际计费的输出 token 数是所有推理 token 加上最终回复的 token 数。由于 Litefuse 看不到推理 token,因此对于没有提供 token 用量的 generation 无法推断正确的成本。
要想从 Litefuse 的成本追踪中受益,请在上报 o1 模型 generation 时提供 token 用量。当使用 Litefuse 的 OpenAI 包装器 或 Langchain、LlamaIndex、LiteLLM 等集成时,token 用量会自动收集并提供。
更多细节请参阅 OpenAI 关于推理模型工作机制的指南。
故障排查
- 修改模型定义后,更新后的成本只会应用到之后写入 Litefuse 的新 generation。
- 只有
generation和embedding类型的 observation 能追踪成本和用量。 - 如果使用 OpenRouter,Litefuse 可以直接捕获 OpenRouter 的成本信息。详情见这里。
- 如果使用 LiteLLM,Litefuse 会直接捕获每个 LiteLLM 响应中返回的成本信息。