Instructor - 可观测性与 Tracing
什么是 Instructor? Instructor (GitHub) 是一个用于获取结构化 LLM 输出的常用库。Instructor 让你可以可靠地从 GPT-3.5、GPT-4、GPT-4-Vision 等大语言模型(包括 Together、Anyscale、Ollama、llama-cpp-python 上的 Mistral/Mixtral 等开源模型)获取 JSON 等结构化数据。它通过利用 Function Calling、Tool Calling 以及 JSON mode、JSON Schema 等约束采样模式,以简洁、透明、用户中心的设计脱颖而出。在底层,Instructor 借助 Pydantic 完成核心工作,并在其之上提供简单易用的 API,帮助你管理校验上下文、用 Tenacity 进行重试以及流式处理 List 与部分响应。
什么是 Litefuse? Litefuse 是一个开源的 AI Agent 可观测性与评估平台,帮助团队 trace API 调用、监控性能并调试其 AI 应用中的问题。
这是一份带有 Litefuse Python 集成示例的 cookbook。
设置
%pip install langfuse openai pydantic instructor --upgrade使用 Litefuse UI 中项目设置页的 API Key 初始化 Langfuse 客户端,并将其加入你的环境。
import os
# Get keys for your project from the project settings page: https://litefuse.cloud
os.environ["LANGFUSE_PUBLIC_KEY"] = "pk-lf-..."
os.environ["LANGFUSE_SECRET_KEY"] = "sk-lf-..."
os.environ["LANGFUSE_BASE_URL"] = "https://litefuse.cloud"
# Your openai key
os.environ["OPENAI_API_KEY"] = "sk-proj-..."快速开始
将 Instructor 与 Litefuse 一起使用非常简单。我们使用 Litefuse OpenAI 集成,并直接用 instructor patch 该客户端。同步与异步客户端均适用。
在同步 OpenAI 客户端中使用 Litefuse-Instructor 集成
import instructor
from langfuse.openai import OpenAI
from pydantic import BaseModel
# Patch Langfuse wrapper of synchronous OpenAI client with instructor
client = instructor.patch(OpenAI())
class WeatherDetail(BaseModel):
city: str
temperature: int
# Run synchronous OpenAI client
weather_info = client.chat.completions.create(
model="gpt-4o",
response_model=WeatherDetail,
messages=[
{"role": "user", "content": "The weather in Paris is 18 degrees Celsius."},
],
)
print(weather_info.model_dump_json(indent=2))
"""
{
"city": "Paris",
"temperature": 18
}
"""在异步 OpenAI 客户端中使用 Litefuse-Instructor 集成
import instructor
from langfuse.openai import AsyncOpenAI
from pydantic import BaseModel
# Patch Langfuse wrapper of synchronous OpenAI client with instructor
client = instructor.apatch(AsyncOpenAI())
class WeatherDetail(BaseModel):
city: str
temperature: int
# Run asynchronous OpenAI client
task = client.chat.completions.create(
model="gpt-4o",
response_model=WeatherDetail,
messages=[
{"role": "user", "content": "The weather in Paris is 18 degrees Celsius."},
],
)
response = await task
print(response.model_dump_json(indent=2))
"""
{
"city": "Paris",
"temperature": 18
}
"""示例
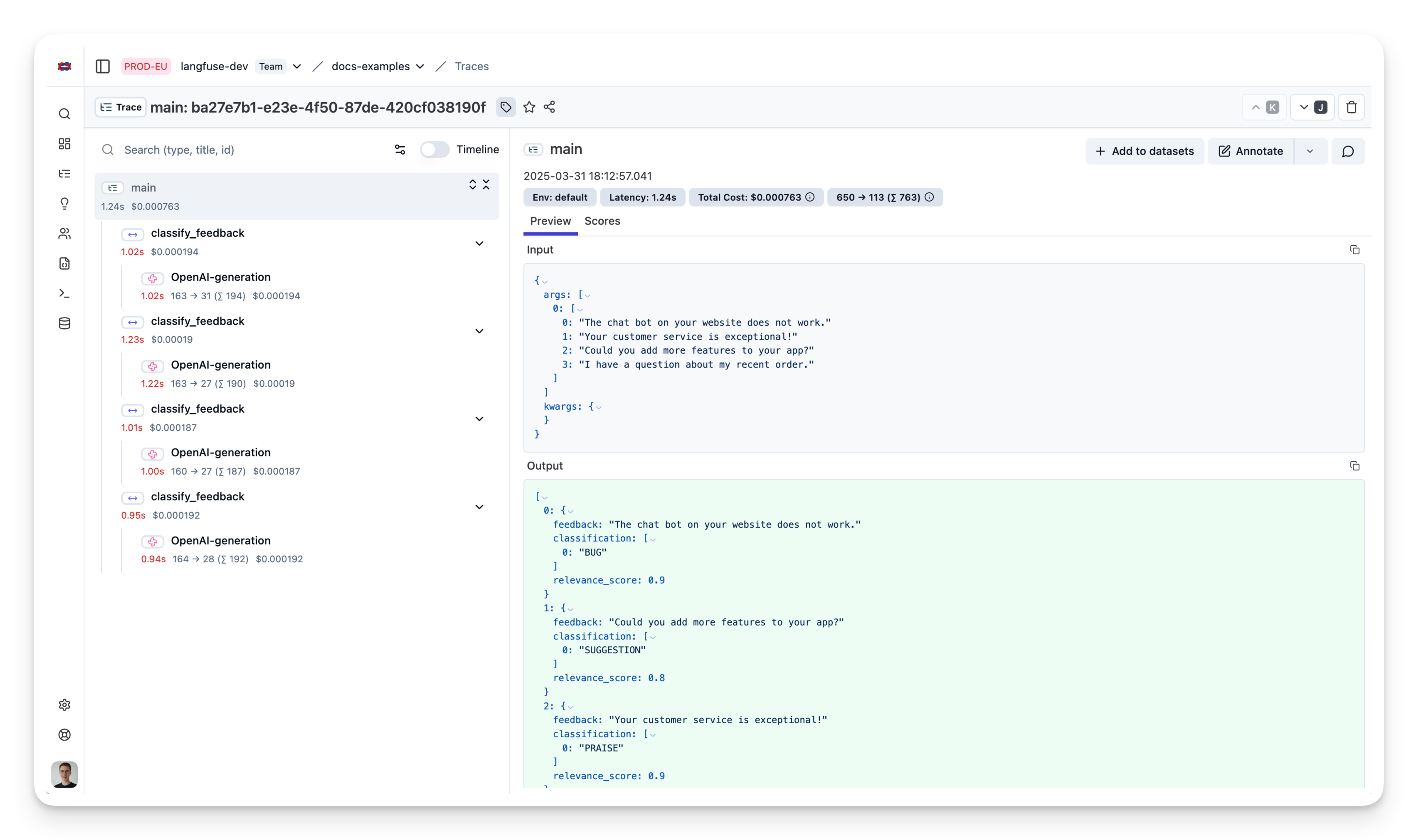
在本示例中,我们首先将客户反馈分类到 PRAISE、SUGGESTION、BUG、QUESTION 等类别,并进一步在 0.0 到 1.0 区间为每条反馈对业务的相关性打分。本例中,我们使用异步 OpenAI 客户端 AsyncOpenAI 对反馈进行分类与评估。
from typing import List, Tuple
from enum import Enum
import asyncio
import instructor
from langfuse.openai import AsyncOpenAI
from langfuse import observe, get_client
from pydantic import BaseModel, Field, field_validator
# Initialize Langfuse wrapper of AsyncOpenAI client
client = AsyncOpenAI()
# Patch the client with Instructor
client = instructor.patch(client, mode=instructor.Mode.TOOLS)
# Initialize Langfuse (needed for scoring)
langfuse = get_client()
# Rate limit the number of requests
sem = asyncio.Semaphore(5)
# Define feedback categories
class FeedbackType(Enum):
PRAISE = "PRAISE"
SUGGESTION = "SUGGESTION"
BUG = "BUG"
QUESTION = "QUESTION"
# Model for feedback classification
class FeedbackClassification(BaseModel):
feedback_text: str = Field(...)
classification: List[FeedbackType] = Field(description="Predicted categories for the feedback")
relevance_score: float = Field(
default=0.0,
description="Score of the query evaluating its relevance to the business between 0.0 and 1.0"
)
# Make sure feedback type is list
@field_validator("classification", mode="before")
def validate_classification(cls, v):
if not isinstance(v, list):
v = [v]
return v
@observe() # Langfuse decorator to automatically log spans to Litefuse
async def classify_feedback(feedback: str) -> Tuple[FeedbackClassification, float]:
"""
Classify customer feedback into categories and evaluate relevance.
"""
async with sem: # simple rate limiting
response = await client.chat.completions.create(
model="gpt-4o",
response_model=FeedbackClassification,
max_retries=2,
messages=[
{
"role": "user",
"content": f"Classify and score this feedback: {feedback}",
},
],
)
# Retrieve observation_id of current span
observation_id = langfuse.get_current_observation_id()
return feedback, response, observation_id
def score_relevance(trace_id: str, observation_id: str, relevance_score: float):
"""
Score the relevance of a feedback query in Litefuse given the observation_id.
"""
langfuse.create_score(
trace_id=trace_id,
observation_id=observation_id,
name="feedback-relevance",
value=relevance_score
)
@observe() # Langfuse decorator to automatically log trace to Litefuse
async def main(feedbacks: List[str]):
tasks = [classify_feedback(feedback) for feedback in feedbacks]
results = []
for task in asyncio.as_completed(tasks):
feedback, classification, observation_id = await task
result = {
"feedback": feedback,
"classification": [c.value for c in classification.classification],
"relevance_score": classification.relevance_score,
}
results.append(result)
# Retrieve trace_id of current trace
trace_id = langfuse.get_current_trace_id()
# Score the relevance of the feedback in Litefuse
score_relevance(trace_id, observation_id, classification.relevance_score)
# Flush observations to Litefuse
langfuse.flush()
return results
feedback_messages = [
"The chat bot on your website does not work.",
"Your customer service is exceptional!",
"Could you add more features to your app?",
"I have a question about my recent order.",
]
feedback_classifications = await main(feedback_messages)
for classification in feedback_classifications:
print(f"Feedback: {classification['feedback']}")
print(f"Classification: {classification['classification']}")
print(f"Relevance Score: {classification['relevance_score']}")
"""
Feedback: I have a question about my recent order.
Classification: ['QUESTION']
Relevance Score: 0.0
Feedback: Could you add more features to your app?
Classification: ['SUGGESTION']
Relevance Score: 0.0
Feedback: The chat bot on your website does not work.
Classification: ['BUG']
Relevance Score: 0.9
Feedback: Your customer service is exceptional!
Classification: ['PRAISE']
Relevance Score: 0.9
"""
Interoperability with the Python SDK
You can use this integration together with the Litefuse SDKs to add additional attributes to the observation.
The @observe() decorator provides a convenient way to automatically wrap your instrumented code and add additional attributes to the observation.
from langfuse import observe, propagate_attributes, get_client
langfuse = get_client()
@observe()
def my_llm_pipeline(input):
# Add additional attributes (user_id, session_id, metadata, version, tags) to all spans created within this execution scope
with propagate_attributes(
user_id="user_123",
session_id="session_abc",
tags=["agent", "my-observation"],
metadata={"email": "user@litefuse.ai"},
version="1.0.0"
):
# YOUR APPLICATION CODE HERE
result = call_llm(input)
return result
# Run the function
my_llm_pipeline("Hi")Learn more about using the Decorator in the Langfuse SDK instrumentation docs.
Troubleshooting
No observations appearing
First, enable debug mode in the Python SDK:
export LANGFUSE_DEBUG="True"Then run your application and check the debug logs:
- OTel observations appear in the logs: Your application is instrumented correctly but observations are not reaching Litefuse. To resolve this:
- Call
langfuse.flush()at the end of your application to ensure all observations are exported. - Verify that you are using the correct API keys and base URL.
- Call
- No OTel spans in the logs: Your application is not instrumented correctly. Make sure the instrumentation runs before your application code.
Unwanted observations in Litefuse
The Langfuse SDK is based on OpenTelemetry. Other libraries in your application may emit OTel spans that are not relevant to you. These still count toward your billable units, so you should filter them out. See Unwanted spans in Litefuse for details.
Missing attributes
Some attributes may be stored in the metadata object of the observation rather than being mapped to the Litefuse data model. If a mapping or integration does not work as expected, please raise an issue on GitHub.
Next Steps
Once you have instrumented your code, you can manage, evaluate and debug your application: