LangChain Tracing 与 LangGraph 集成
Litefuse 通过 LangChain Callbacks 与 LangChain 集成 —— 这是钩入 LangChain 组件执行过程的标准机制。Litefuse CallbackHandler 会自动捕获 LangChain 执行、LLM、工具和 retriever 的详细 trace,用于评估和调试你的应用。
什么是 LangChain? LangChain 是一个开源框架,通过提供将模型与外部数据、API 和逻辑连接起来的工具,帮助开发者构建由大语言模型(LLM)驱动的应用。
什么是 LangGraph? LangGraph 是构建在 LangChain 之上的框架,使用基于图的架构,更易于设计和运行有状态、多步骤的 AI Agent。
什么是 Litefuse? Litefuse 是一个用于 LLM 应用可观测性与 tracing 的平台。它会捕获 LLM 交互过程中发生的一切:输入、输出、工具使用、重试、延迟和成本,让你能够评估并调试你的应用。
快速开始
安装依赖
pip install langfuse langchain langchain_openai langgraph初始化 Litefuse Callback Handler
接下来,设置你的 Litefuse API Key。可通过注册免费的 Litefuse Cloud 账号或 自托管 Litefuse 获取这些 Key。这些环境变量是 Langfuse 客户端鉴权并向 Litefuse 项目发送数据所必需的。
LANGFUSE_SECRET_KEY = "sk-lf-..."
LANGFUSE_PUBLIC_KEY = "pk-lf-..."
LANGFUSE_BASE_URL = "https://litefuse.cloud"
OPENAI_API_KEY = "sk-proj-..."设置好环境变量后,我们就可以初始化 Langfuse Client 与 CallbackHandler。你也可以使用 构造参数 来初始化 Langfuse 客户端。
from langfuse import get_client
from langfuse.langchain import CallbackHandler
# Initialize Langfuse client
langfuse = get_client()
# Initialize Langfuse CallbackHandler for Langchain (tracing)
langfuse_handler = CallbackHandler()LangChain 示例
对 LangGraph 进行 instrument 的方式相同。只需将 langfuse_handler 传给 Agent 调用。(示例 Notebook)。
from langchain.agents import create_agent
def add_numbers(a: int, b: int) -> int:
"""Add two numbers together and return the result."""
return a + b
agent = create_agent(
model="openai:gpt-5-mini",
tools=[add_numbers],
system_prompt="You are a helpful math tutor who can do calculations using the provided tools.",
)
# Run the agent
agent.invoke(
{"messages": [{"role": "user", "content": "what is 42 + 58?"}]},
config={"callbacks": [langfuse_handler]}
)在 Litefuse 中查看 Trace
执行应用后,进入你的 Litefuse Trace 表。你将看到应用执行的详细 trace,包括 LLM 调用、检索操作、输入、输出以及性能指标的洞察。
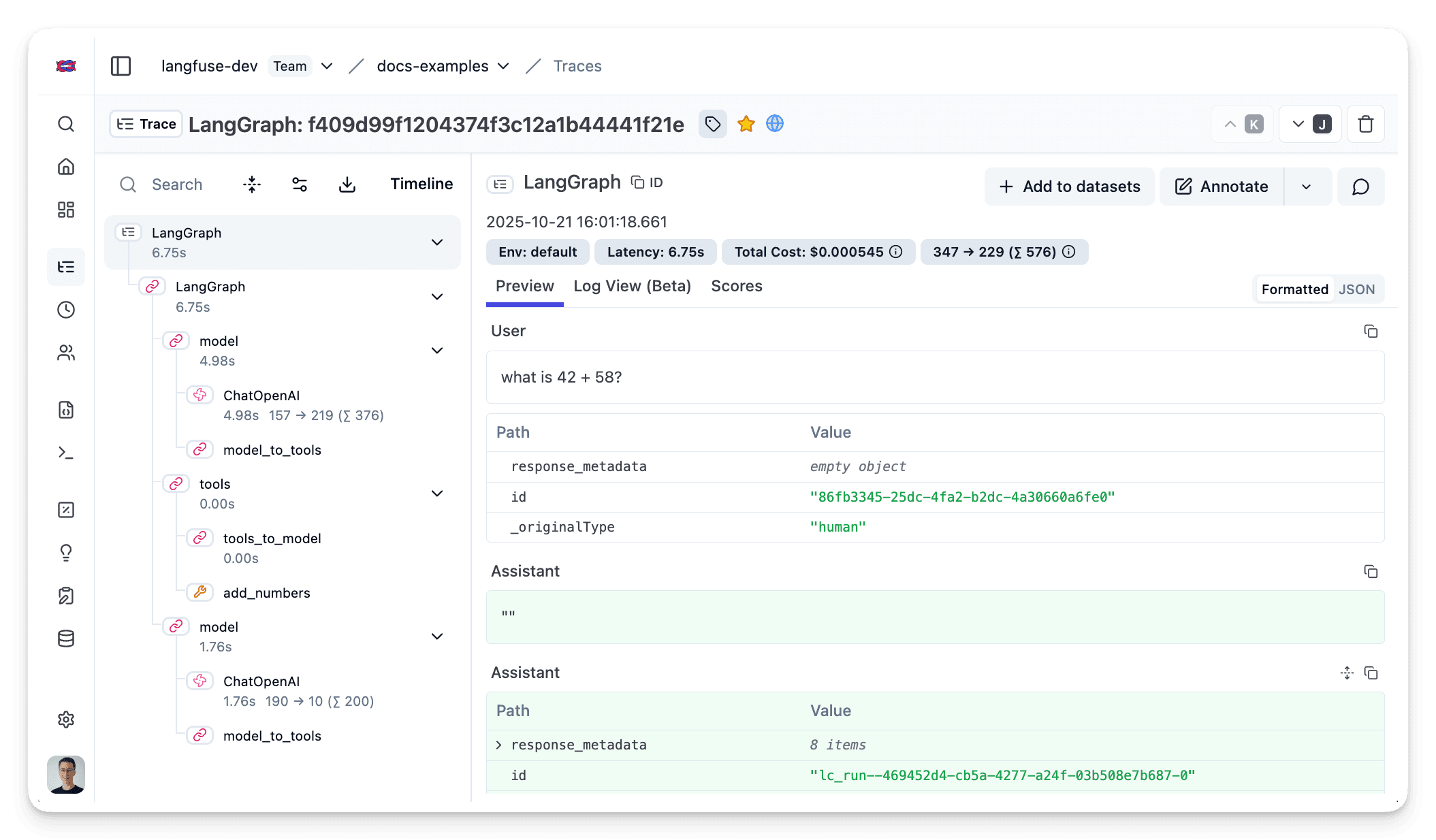
示例 Notebook
进阶配置
与 Langfuse SDK 互操作
LangChain 集成可以与 Langfuse SDK 无缝配合,创建综合性 trace,将 LangChain 操作与其他应用逻辑组合在一起。
常见用例:
- 向 trace 中添加非 LangChain 相关的 observation
- 将多次 LangChain 运行归并到同一条 trace 中
- 设置 trace 级属性(
user_id、session_id、tags等)
使用 @observe() 装饰器:
from langfuse import observe, get_client, propagate_attributes
from langfuse.langchain import CallbackHandler
from langchain_openai import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate
@observe() # Automatically log function as a trace to Litefuse
def process_user_query(user_input: str):
langfuse = get_client()
# Propagate trace attributes to all child observations
with propagate_attributes(
trace_name="user-query-processing",
session_id="session-1234",
user_id="user-5678",
):
# Initialize the Langfuse handler - automatically inherits the current trace context
langfuse_handler = CallbackHandler()
# Your Langchain code - will be nested under the @observe trace
llm = ChatOpenAI(model_name="gpt-4o")
prompt = ChatPromptTemplate.from_template("Respond to: {input}")
chain = prompt | llm
result = chain.invoke({"input": user_input}, config={"callbacks": [langfuse_handler]})
# Set trace I/O (deprecated — only for backward compat with legacy trace-level LLM-as-a-judge evaluators)
langfuse.set_current_trace_io(
input={"query": user_input},
output={"response": result.content},
)
return result.content
# Usage
answer = process_user_query("What is the capital of France?")实际示例请参阅 LangChain + 装饰器可观测性 cookbook。
使用上下文管理器:
from langfuse import get_client, propagate_attributes
from langfuse.langchain import CallbackHandler
from langchain_openai import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate
langfuse = get_client()
# Create a trace via Langfuse spans and use Langchain within it
with langfuse.start_as_current_observation(as_type="span", name="multi-step-process") as root_span:
# Update trace attributes
with propagate_attributes(
session_id="session-1234",
user_id="user-5678",
):
# Initialize the Langfuse handler
langfuse_handler = CallbackHandler()
# Step 1: Initial processing (custom logic)
with langfuse.start_as_current_observation(as_type="span", name="input-preprocessing") as prep_span:
processed_input = "Simplified: Explain quantum computing"
prep_span.update(output={"processed_query": processed_input})
# Step 2: LangChain processing
llm = ChatOpenAI(model_name="gpt-4o")
prompt = ChatPromptTemplate.from_template("Answer this question: {input}")
chain = prompt | llm
result = chain.invoke(
{"input": processed_input},
config={"callbacks": [langfuse_handler]}
)
# Step 3: Post-processing (custom logic)
with langfuse.start_as_current_observation(as_type="span", name="output-postprocessing") as post_span:
final_result = f"Response: {result.content}"
post_span.update(output={"final_response": final_result})
# Set trace I/O (deprecated — only for backward compat with legacy trace-level LLM-as-a-judge evaluators)
root_span.set_trace_io(
input={"user_query": "Explain quantum computing"},
output={"final_answer": final_result}
)Trace 属性
你可以为每次 LangChain 执行动态设置 trace 属性,例如 user_id、session_id 和 tags。
在 Python SDK 中,你有两种方式来动态设置 trace 属性:
方式 1:通过 chain 调用中的 metadata 字段(最简单):
from langfuse.langchain import CallbackHandler
from langchain_openai import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate
langfuse_handler = CallbackHandler()
llm = ChatOpenAI(model_name="gpt-4o")
prompt = ChatPromptTemplate.from_template("Tell me a joke about {topic}")
chain = prompt | llm
# Set trace attributes dynamically via metadata
response = chain.invoke(
{"topic": "cats"},
config={
"callbacks": [langfuse_handler],
"metadata": {
"langfuse_user_id": "random-user",
"langfuse_session_id": "random-session",
"langfuse_tags": ["random-tag-1", "random-tag-2"]
}
}
)方式 2:使用 Langfuse SDK
Trace ID 与分布式 Tracing
要给 LangChain 执行传入自定义的 trace_id,可以将该执行包装在一个设置预定义 trace ID 的 span 中。你也可以通过 langfuse_handler.last_trace_id 获取回调处理器创建的最后一个 trace ID。
from langfuse import get_client, Langfuse
from langfuse.langchain import CallbackHandler
langfuse = get_client()
# Generate deterministic trace ID from external system
external_request_id = "req_12345"
predefined_trace_id = Langfuse.create_trace_id(seed=external_request_id)
langfuse_handler = CallbackHandler()
# Use the predefined trace ID with trace_context
with langfuse.start_as_current_observation(
as_type="span",
name="langchain-request",
trace_context={"trace_id": predefined_trace_id}
) as span:
# Set trace I/O (deprecated — only for backward compat with legacy trace-level LLM-as-a-judge evaluators)
span.set_trace_io(
input={"person": "Ada Lovelace"}
)
with propagate_attributes(
user_id="user_123",
):
# LangChain execution will be part of this trace
response = chain.invoke(
{"person": "Ada Lovelace"},
config={"callbacks": [langfuse_handler]}
)
span.set_trace_io(output={"response": response})
print(f"Trace ID: {predefined_trace_id}") # Use this for scoring later
print(f"Trace ID: {langfuse_handler.last_trace_id}") # Care needed in concurrent environments where handler is reused给 Trace 打分
在 Litefuse 中给 LangChain trace 打分有多种方式。更多细节参见 评分文档。
from langfuse import get_client
langfuse = get_client()
# Option 1: Use the yielded span object from the context manager
with langfuse.start_as_current_observation(
as_type="span",
name="langchain-request",
trace_context={"trace_id": predefined_trace_id}
) as span:
# ... LangChain execution ...
# Score using the span object
span.score_trace(
name="user-feedback",
value=1,
data_type="NUMERIC",
comment="This was correct, thank you"
)
# Option 2: Use langfuse.score_current_trace() if still in context
with langfuse.start_as_current_observation(as_type="span", name="langchain-request") as span:
# ... LangChain execution ...
# Score using current context
langfuse.score_current_trace(
name="user-feedback",
value=1,
data_type="NUMERIC"
)
# Option 3: Use create_score() with trace ID (when outside context)
langfuse.create_score(
trace_id=predefined_trace_id,
name="user-feedback",
value=1,
data_type="NUMERIC",
comment="This was correct, thank you"
)队列与刷新
Langfuse SDK 会在后台对事件进行队列化与批处理,以减少网络请求次数并提升整体性能。在长时间运行的应用中,无需额外配置即可工作。
如果你运行的是短生命周期的应用,需要关闭 Litefuse 以确保所有事件在应用退出前被刷新。
from langfuse import get_client
# Shutdown the underlying singleton instance
get_client().shutdown()如果你想在某个时间点同步刷新事件,可以使用 flush 方法。它会等待后台队列中的所有事件都被发送到 Litefuse API。一般不建议在生产环境中使用此方法。
from langfuse import get_client
# Flush the underlying singleton instance
get_client().flush()Serverless 环境(JS/TS)
自 Langchain 0.3.0 版本起,Litefuse 所依赖的回调被改为后台执行。这意味着执行不会等待回调返回再继续。在 0.3.0 之前的版本中,行为正好相反。如果你在 Google Cloud Functions、AWS Lambda 或 Cloudflare Workers 等 serverless 环境中运行代码,应该将回调设置为阻塞式,使其有时间完成或超时。可以通过以下方式实现:
- 将环境变量
LANGCHAIN_CALLBACKS_BACKGROUND设为 “false” - 导入全局
awaitAllCallbacks方法以确保所有回调在必要时完成
更多关于 await callbacks 的信息请查阅 Langchain 文档。
AWS Bedrock AgentCore
将 LangChain 应用部署到 AWS Bedrock AgentCore 时,运行时的 ADOT (AWS Distro for OpenTelemetry) 自动 instrumentation 要求使用 OTEL 配置,而不能仅依赖 Litefuse callback handler。配置细节请参阅 在已有 OpenTelemetry 配置下使用 Litefuse,或完整的 Amazon Bedrock AgentCore 集成指南。
Azure OpenAI 模型名称
请向 AzureOpenAI 或 AzureChatOpenAI 类添加 model 关键字参数,以便在 Litefuse 中正确解析模型名称。
from langchain_openai import AzureChatOpenAI
llm = AzureChatOpenAI(
azure_deployment="my-gpt-4o-deployment",
model="gpt-4o",
)Langchain 集成升级路径
本文是不同版本集成的升级路径合集。如果你要将集成添加到你的项目中,请从最新版本开始,并按照上面的集成指南操作。
Litefuse 与 Langchain 都在积极开发。因此,我们也不断改进集成。这意味着我们有时需要对 API 做破坏性更改,或者响应 Langchain 的破坏性变更。我们会尽量将这些变更控制在最小范围,并在做出变更时提供清晰的升级路径。
Python
JS/TS
Python
从 v2.x.x 升级到 v3.x.x
Python SDK v3 引入了完全重新设计的 Litefuse 核心,提供新的可观测性 API。虽然 LangChain 集成仍然依赖 CallbackHandler,但几乎所有用法都发生了变化。下表突出显示了最重要的破坏性变更:
| 主题 | v2 | v3 |
|---|---|---|
| 包导入 | from langfuse.callback import CallbackHandler | from langfuse.langchain import CallbackHandler |
| 客户端处理 | 多个实例化客户端 | 单例模式,通过 get_client() 访问 |
| Trace/Span 上下文 | CallbackHandler 可选地接受 root 来分组运行 | 使用上下文管理器 with langfuse.start_as_current_observation(...) |
| 动态 trace 属性 | 通过 LangChain config 传入(例如 metadata["langfuse_user_id"]) | 使用 metadata["langfuse_user_id"] 或 propagate_attributes(user_id=...) |
| 构造参数 | CallbackHandler(sample_rate=..., user_id=...) | 不再接受构造参数 —— 请使用 Langfuse client 或 span |
最小化迁移示例:
# Install latest SDK (>=3.0.0)
pip install --upgrade langfuse
# v2 Code (for reference)
# from langfuse.callback import CallbackHandler
# handler = CallbackHandler()
# chain.invoke({"topic": "cats"}, config={"callbacks": [handler]})
# v3 Code
from langfuse import Langfuse, get_client
from langfuse.langchain import CallbackHandler
from langchain_openai import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate
# 1. Create/Configure Langfuse client (once at startup)
Langfuse(
public_key="your-public-key",
secret_key="your-secret-key",
)
# 2. Access singleton instance and create handler
langfuse = get_client()
handler = CallbackHandler()
# 3. Option 1: Use metadata in chain invocation (simplest migration)
llm = ChatOpenAI(model_name="gpt-4o")
prompt = ChatPromptTemplate.from_template("Tell me a joke about {topic}")
chain = prompt | llm
response = chain.invoke(
{"topic": "cats"},
config={
"callbacks": [handler],
"metadata": {"langfuse_user_id": "user_123"}
}
)
# (Optional) Flush events in short-lived scripts
langfuse.flush()- 所有诸如
sample_rate或tracing_enabled之类的参数现在必须在构造 Litefuse 客户端时(或通过环境变量)提供,不再在 handler 上设置。 flush()和shutdown()等函数已移到客户端实例上(get_client().flush())。
从 v1.x.x 升级到 v2.x.x
CallbackHandler 可以在 LangChain chain 的多次调用中复用,如下所示。
from langfuse.callback import CallbackHandler
langfuse_handler = CallbackHandler(PUBLIC_KEY, SECRET_KEY)
# Setup Langchain
from langchain.chains import LLMChain
...
chain = LLMChain(llm=llm, prompt=prompt, callbacks=[langfuse_handler])
# Add Langfuse handler as callback
chain.run(input="<first_user_input>", callbacks=[langfuse_handler])
chain.run(input="<second_user_input>", callbacks=[langfuse_handler])
此前,多次调用 chain 会把 observation 都归入同一条 trace。
TRACE
|
|-- SPAN: Retrieval
| |
| |-- SPAN: LLM Chain
| | |
| | |-- GENERATION: ChatOpenAi
|-- SPAN: Retrieval
| |
| |-- SPAN: LLM Chain
| | |
| | |-- GENERATION: ChatOpenAi我们更改了这一行为,使每次调用都会落到独立的 trace 上。这样我们就能推导出 LangChain 应用的用户输入与输出。
TRACE_1
|
|-- SPAN: Retrieval
| |
| |-- SPAN: LLM Chain
| | |
| | |-- GENERATION: ChatOpenAi
TRACE_2
|
|-- SPAN: Retrieval
| |
| |-- SPAN: LLM Chain
| | |
| | |-- GENERATION: ChatOpenAi如果你仍想将多次调用归并到一条 trace 上,可以使用 Langfuse SDK 与 LangChain 集成结合使用(更多细节)。
from langfuse import Langfuse
langfuse = Langfuse()
# Get Langchain handler for a trace
trace = langfuse.trace()
langfuse_handler = trace.get_langchain_handler()
# langfuse_handler will use the trace for all invocationsJS/TS
从 v2.x.x 升级到 v3.x.x
需要 langchain ^0.1.10。Langchain 发布了新的稳定版 Callback Handler 接口,本版本的 Langfuse SDK 实现了它。旧版本不再受支持。
从 v1.x.x 升级到 v2.x.x
CallbackHandler 可以在 LangChain chain 的多次调用中复用,如下所示。
import { CallbackHandler } from "@langfuse/langchain";
// create a handler
const langfuseHandler = new CallbackHandler({
publicKey: LANGFUSE_PUBLIC_KEY,
secretKey: LANGFUSE_SECRET_KEY,
});
import { LLMChain } from "langchain/chains";
// create a chain
const chain = new LLMChain({
llm: model,
prompt,
callbacks: [langfuseHandler],
});
// execute the chain
await chain.call(
{ product: "<user_input_one>" },
{ callbacks: [langfuseHandler] }
);
await chain.call(
{ product: "<user_input_two>" },
{ callbacks: [langfuseHandler] }
);此前,多次调用 chain 会把 observation 都归入同一条 trace。
TRACE
|
|-- SPAN: Retrieval
| |
| |-- SPAN: LLM Chain
| | |
| | |-- GENERATION: ChatOpenAi
|-- SPAN: Retrieval
| |
| |-- SPAN: LLM Chain
| | |
| | |-- GENERATION: ChatOpenAi我们更改了这一行为,使每次调用都会落到独立的 trace 上。这是更符合大多数用户期望的默认设置。
TRACE_1
|
|-- SPAN: Retrieval
| |
| |-- SPAN: LLM Chain
| | |
| | |-- GENERATION: ChatOpenAi
TRACE_2
|
|-- SPAN: Retrieval
| |
| |-- SPAN: LLM Chain
| | |
| | |-- GENERATION: ChatOpenAi如果你仍想将多次调用归并到一条 trace 上,可以使用 Langfuse SDK 与 LangChain 集成结合使用(更多细节)。
const trace = langfuse.trace({ id: "special-id" });
// CallbackHandler will use the trace with the id "special-id" for all invocations
const langfuseHandler = new CallbackHandler({ root: trace });