使用 Cleanlab 进行自动化评估
Cleanlab 的 可信赖语言模型(TLM)让 Litefuse 用户能够快速识别任意 LLM trace 中质量低劣或产生幻觉的回答。
什么是 TLM?
TLM 是一款自动评估工具,为每一次 LLM 输出添加可靠性和可解释性。TLM 会自动找出潜伏在你的生产日志和 trace 中质量较差或不正确的 LLM 回答。这帮助你在不必花费大量人工审查和标注的情况下,进行更出色的评估。TLM 还可以基于每次 LLM 输出的可信度评分,为 LLM 自动化回答和决策提供智能路由能力。
TLM 为用户提供:
- 针对每个 LLM 回答的可信度评分和解释
- 更高的准确率:严格的 基准测试 表明,TLM 始终比 GPT 4/4o、Claude 等其他 LLM 产生更准确的结果。
- 可扩展的 API:TLM 设计用于处理大规模数据集,适用于大多数企业级应用,包括数据抽取、打标签、问答(RAG)等。
快速开始
本指南将带你完成使用 Cleanlab 可信赖语言模型(TLM)评估 Litefuse 中所捕获 LLM 回答的全过程。
安装依赖并设置环境变量
注意: 新的 Python SDK(v3)已发布——我们提供了基于 OpenTelemetry 的全新升级版 SDK。请查看 SDK v3,它更强大、使用更简单。
%pip install "langfuse<3.0.0" openai cleanlab-tlmimport os
import pandas as pd
from getpass import getpass
import dotenv
dotenv.load_dotenv()API Key
本指南需要 Cleanlab TLM API Key。如果你还没有,可以在 此处 注册免费试用。
本指南需要四个 API Key:
# Get keys for your project from the project settings page: https://litefuse.cloud
os.environ["LANGFUSE_PUBLIC_KEY"] = "pk-lf-..."
os.environ["LANGFUSE_SECRET_KEY"] = "sk-lf-..."
os.environ["LANGFUSE_BASE_URL"] = "https://litefuse.cloud"
os.environ["OPENAI_API_KEY"] = "<openai_api_key>"
os.environ["CLEANLAB_TLM_API_KEY"] = "<cleanlab_tlm_api_key>"准备 trace 数据集并加载到 Litefuse
为了演示目的,我们会简单地生成一些 trace 并在 Litefuse 中追踪它们。通常情况下,你应该已经在 Litefuse 中捕获了 trace,并可以直接跳到 “从 Litefuse 下载 trace 数据集”。
注意:TLM 要求提供 LLM 的完整输入。这包括所有原本提供给 LLM 用于生成回答的 system prompt、上下文或其他信息。请注意,下面我们将 system prompt 包含在 trace 的 metadata 中,因为 trace 默认不会在输入中包含 system prompt。
from langfuse.decorators import langfuse_context, observe
from openai import OpenAI
openai = OpenAI()# Let's use some tricky trivia questions to generate some traces
trivia_questions = [
"What is the 3rd month of the year in alphabetical order?",
"What is the capital of France?",
"How many seconds are in 100 years?",
"Alice, Bob, and Charlie went to a café. Alice paid twice as much as Bob, and Bob paid three times as much as Charlie. If the total bill was $72, how much did each person pay?",
"When was the Declaration of Independence signed?"
]
@observe()
def generate_answers(trivia_question):
system_prompt = "You are a trivia master."
# Update the trace with the question
langfuse_context.update_current_trace(
name=f"Answering question: '{trivia_question}'",
tags=["TLM_eval_pipeline"],
metadata={"system_prompt": system_prompt}
)
response = openai.chat.completions.create(
model="gpt-3.5-turbo",
messages=[
{"role": "system", "content": system_prompt},
{"role": "user", "content": trivia_question},
],
)
answer = response.choices[0].message.content
return answer
# Generate answers
answers = []
for i in range(len(trivia_questions)):
answer = generate_answers(trivia_questions[i])
answers.append(answer)
print(f"Question {i+1}: {trivia_questions[i]}")
print(f"Answer {i+1}:\n{answer}\n")
print(f"Generated {len(answers)} answers and tracked them in Litefuse.")Question 1: What is the 3rd month of the year in alphabetical order?
Answer 1:
March
Question 2: What is the capital of France?
Answer 2:
The capital of France is Paris.
Question 3: How many seconds are in 100 years?
Answer 3:
There are 31,536,000 seconds in a year (60 seconds x 60 minutes x 24 hours x 365 days). Therefore, in 100 years, there would be 3,153,600,000 seconds.
Question 4: Alice, Bob, and Charlie went to a café. Alice paid twice as much as Bob, and Bob paid three times as much as Charlie. If the total bill was $72, how much did each person pay?
Answer 4:
Let's call the amount Charlie paid x.
Alice paid twice as much as Bob, so she paid 2*(3x) = 6x.
Bob paid three times as much as Charlie, so he paid 3x.
We know the total bill was $72:
x + 6x + 3x = 72
10x = 72
x = 7.2
Therefore, Charlie paid $7.20, Bob paid $21.60, and Alice paid $43.20.
Question 5: When was the Declaration of Independence signed?
Answer 5:
The Declaration of Independence was signed on July 4, 1776.
Generated 5 answers and tracked them in Litefuse.记住,本教程的目标是向你展示如何构建一个外部评估流水线。这些流水线会运行在你的 CI/CD 环境中,或运行在不同的编排容器服务里。无论选择哪种环境,以下三个关键步骤始终适用:
- 获取你的 trace:将应用 trace 拿到你的评估环境中
- 执行评估:应用任何你偏好的评估逻辑
- 保存评估结果:将评估结果回写到用于计算它们的 Litefuse trace 上。
在 notebook 的剩余部分,我们只有一个目标:
🎯 目标:评估过去 24 小时内运行的所有 trace
从 Litefuse 下载 trace 数据集
从 Litefuse 获取 trace 非常直接。只需配置好 Langfuse 客户端,并使用其中一个函数获取数据即可。我们会获取 trace 并对它们进行评估。之后,我们会把分数写回 Litefuse。
fetch_traces() 函数支持按 tag、时间戳等参数过滤 trace。关于其他查询 trace 的方法,详见我们的文档。
from langfuse import Langfuse
from datetime import datetime, timedelta
langfuse = Langfuse()
now = datetime.now()
one_day_ago = now - timedelta(hours=24)
traces = langfuse.fetch_traces(
tags="TLM_eval_pipeline",
from_timestamp=one_day_ago,
to_timestamp=now,
).data
使用 TLM 生成评估
Litefuse 可以处理数值型、布尔型和分类型(string)评分。将你的自定义评估逻辑封装成函数通常是个好习惯。
我们不会对每个 trace 单独运行 TLM,而是将所有 prompt、response 对作为列表一次性传给 TLM。这样效率更高,并能一次性获得所有 trace 的分数和解释。然后,借助 trace.id,我们可以将分数和解释关联回 Litefuse 中正确的 trace。
from cleanlab_tlm import TLM
tlm = TLM(options={"log": ["explanation"]})# This helper method will extract the prompt and response from each trace and return three lists: trace ID's, prompts, and responses.
def get_prompt_response_pairs(traces):
prompts = []
responses = []
for trace in traces:
prompts.append(trace.metadata["system_prompt"] + "\n" + trace.input["args"][0])
responses.append(trace.output)
return prompts, responses
trace_ids = [trace.id for trace in traces]
prompts, responses = get_prompt_response_pairs(traces)现在,让我们使用 TLM 为每个 trace 生成 trustworthiness score 和 explanation。
重要: 必须始终包含原本提供给 LLM 用于生成回答的所有 system prompt、上下文或其他信息。你应当让传给 get_trustworthiness_score() 的 prompt 输入与原始 prompt 尽可能相似。这就是我们将 system prompt 包含在 trace metadata 中的原因。
# Evaluate each of the prompt, response pairs using TLM
evaluations = tlm.get_trustworthiness_score(prompts, responses)
# Extract the trustworthiness scores and explanations from the evaluations
trust_scores = [entry["trustworthiness_score"] for entry in evaluations]
explanations = [entry["log"]["explanation"] for entry in evaluations]
# Create a DataFrame with the evaluation results
trace_evaluations = pd.DataFrame({
'trace_id': trace_ids,
'prompt': prompts,
'response': responses,
'trust_score': trust_scores,
'explanation': explanations
})
trace_evaluationsQuerying TLM... 100%|██████████|| trace_id | prompt | response | trust_score | explanation | |
|---|---|---|---|---|---|
| 0 | 2f0d41b2-9b89-4ba6-8b3f-7dadac8a8fae | You are a trivia master.\nWhen was the Declara... | The Declaration of Independence was signed on ... | 0.389889 | The proposed response states that the Declarat... |
| 1 | f8e91744-3fcb-4ef5-b6c6-7cbcf0773144 | You are a trivia master.\nAlice, Bob, and Char... | Let's denote the amount Charlie paid as C. \n\... | 0.669774 | This response is untrustworthy due to lack of ... |
| 2 | f9b42125-4e5e-4533-bfbb-36c30490bd1d | You are a trivia master.\nHow many seconds are... | There are 3,153,600,000 seconds in 100 years. | 0.499818 | To calculate the number of seconds in 100 year... |
| 3 | 71b131b9-e706-41c7-9bfd-b77719783f29 | You are a trivia master.\nWhat is the capital ... | The capital of France is Paris. | 0.987433 | Did not find a reason to doubt trustworthiness. |
| 4 | da0ee9fa-01cf-42ce-9e3e-e8d127ca105b | You are a trivia master.\nWhat is the 3rd mont... | March. | 0.114874 | To determine the 3rd month of the year in alph... |
太棒了!现在我们有了一个把 trace ID 映射到分数和解释的 DataFrame。出于演示目的,我们还包含了每个 trace 的 prompt 和 response,以便找出最不可信的 trace!
sorted_df = trace_evaluations.sort_values(by="trust_score", ascending=True).head()
sorted_df| trace_id | prompt | response | trust_score | explanation | |
|---|---|---|---|---|---|
| 4 | da0ee9fa-01cf-42ce-9e3e-e8d127ca105b | You are a trivia master.\nWhat is the 3rd mont... | March. | 0.114874 | To determine the 3rd month of the year in alph... |
| 0 | 2f0d41b2-9b89-4ba6-8b3f-7dadac8a8fae | You are a trivia master.\nWhen was the Declara... | The Declaration of Independence was signed on ... | 0.389889 | The proposed response states that the Declarat... |
| 2 | f9b42125-4e5e-4533-bfbb-36c30490bd1d | You are a trivia master.\nHow many seconds are... | There are 3,153,600,000 seconds in 100 years. | 0.499818 | To calculate the number of seconds in 100 year... |
| 1 | f8e91744-3fcb-4ef5-b6c6-7cbcf0773144 | You are a trivia master.\nAlice, Bob, and Char... | Let's denote the amount Charlie paid as C. \n\... | 0.669774 | This response is untrustworthy due to lack of ... |
| 3 | 71b131b9-e706-41c7-9bfd-b77719783f29 | You are a trivia master.\nWhat is the capital ... | The capital of France is Paris. | 0.987433 | Did not find a reason to doubt trustworthiness. |
# Let's look at the least trustworthy trace.
print("Prompt: ", sorted_df.iloc[0]["prompt"], "\n")
print("OpenAI Response: ", sorted_df.iloc[0]["response"], "\n")
print("TLM Trust Score: ", sorted_df.iloc[0]["trust_score"], "\n")
print("TLM Explanation: ", sorted_df.iloc[0]["explanation"])Prompt: You are a trivia master.
What is the 3rd month of the year in alphabetical order?
OpenAI Response: March.
TLM Trust Score: 0.11487442493072615
TLM Explanation: To determine the 3rd month of the year in alphabetical order, we first list the months: January, February, March, April, May, June, July, August, September, October, November, December. When we arrange these months alphabetically, we get: April, August, December, February, January, July, June, March, May, November, October, September. In this alphabetical list, March is the 8th month, not the 3rd. The 3rd month in alphabetical order is actually December. Therefore, the proposed response is incorrect.
This response is untrustworthy due to lack of consistency in possible responses from the model. Here's one inconsistent alternate response that the model considered (which may not be accurate either):
December.太棒了!TLM 成功识别出多个 OpenAI 给出错误答案的 trace。
让我们把 trust_score 和 explanation 列上传到 Litefuse。
将评估结果上传到 Litefuse
for idx, row in trace_evaluations.iterrows():
trace_id = row["trace_id"]
trust_score = row["trust_score"]
explanation = row["explanation"]
# Add the trustworthiness score to the trace with the explanation as a comment
langfuse.score(
trace_id=trace_id,
name="trust_score",
value=trust_score,
comment=explanation
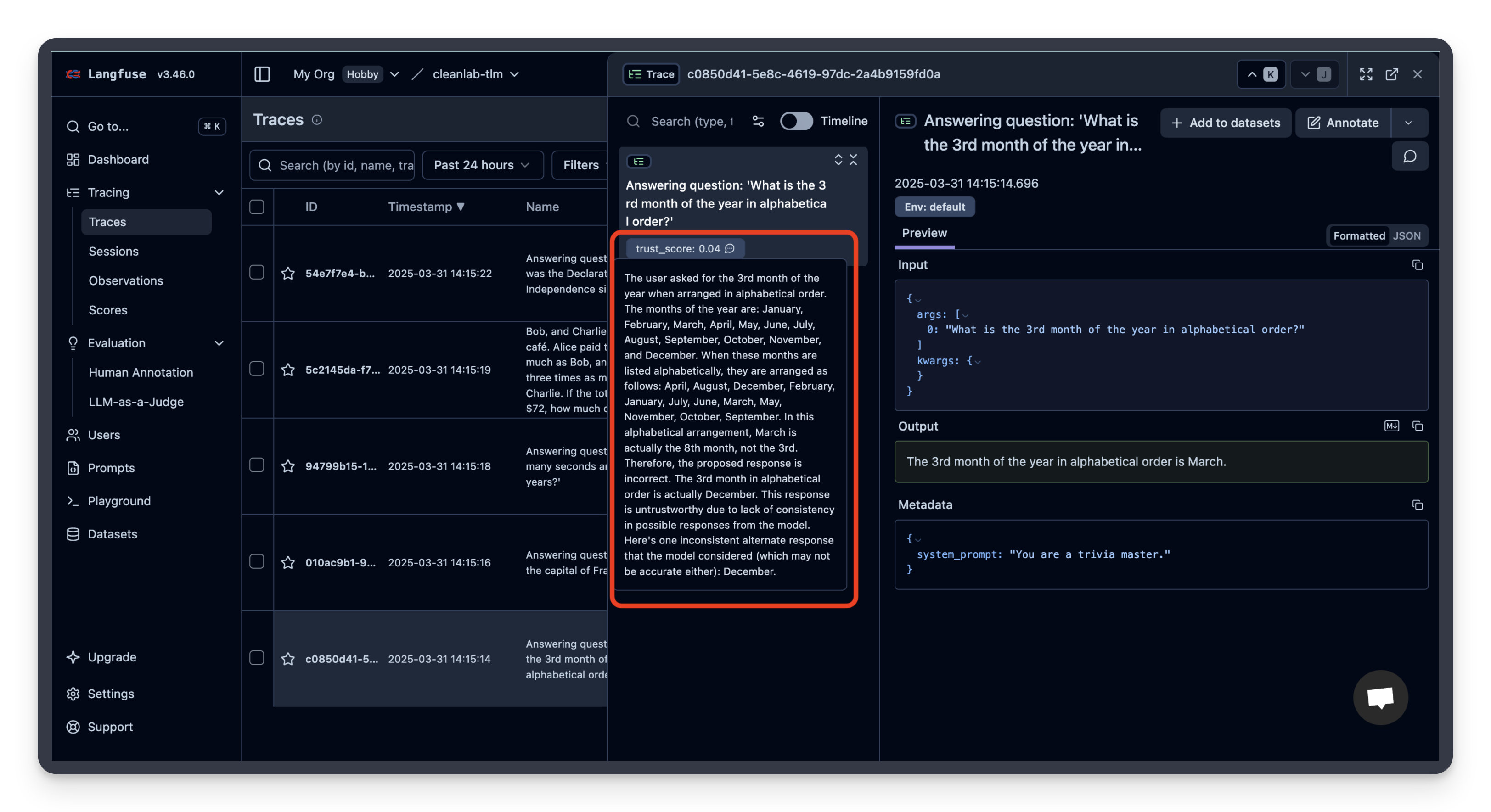
)现在你应该可以在 Litefuse UI 中看到 TLM 的可信度评分和解释了!
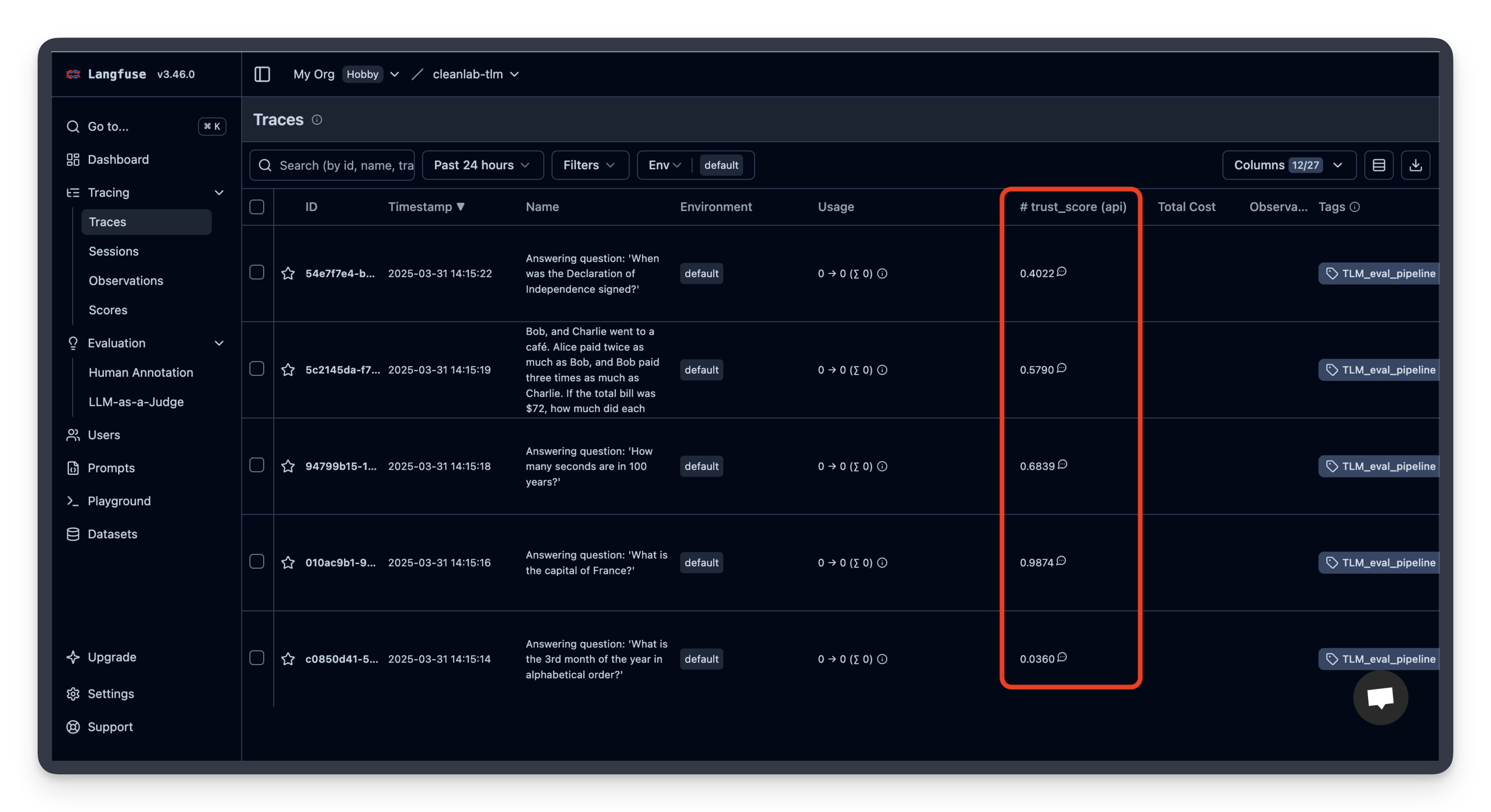
如果你点击某个 trace,还可以看到对应的可信度评分和解释。