使用 UpTrain 评估 Litefuse 的 LLM Trace
UpTrain 的开源库提供了一系列用于评估 LLM 应用的指标。
本 notebook 演示如何在 Litefuse 生成的 trace 上运行 UpTrain 的评估指标。然后你可以在 Litefuse 中持续监控这些 score,或者用它们对比不同实验的效果。
准备工作
你可以在这里获取 Litefuse API key,在这里获取 OpenAI API key。
%pip install langfuse datasets uptrain litellm openai rouge_score --upgradeimport os
# Get keys for your project from the project settings page: https://litefuse.cloud
os.environ["LANGFUSE_PUBLIC_KEY"] = "pk-lf-..."
os.environ["LANGFUSE_SECRET_KEY"] = "sk-lf-..."
os.environ["LANGFUSE_BASE_URL"] = "https://litefuse.cloud"
# Your openai key
os.environ["OPENAI_API_KEY"] = "sk-proj-..."示例数据集
我们用这份数据集来表示你已经写入 Litefuse 的 trace。在生产环境中,你应当使用自己的真实数据。
data = [
{
"question": "What are the symptoms of a heart attack?",
"context": "A heart attack, or myocardial infarction, occurs when the blood supply to the heart muscle is blocked. Chest pain is a good symptom of heart attack, though there are many others.",
"response": "Symptoms of a heart attack may include chest pain or discomfort, shortness of breath, nausea, lightheadedness, and pain or discomfort in one or both arms, the jaw, neck, or back."
},
{
"question": "Can stress cause physical health problems?",
"context": "Stress is the body's response to challenges or threats. Yes, chronic stress can contribute to various physical health problems, including cardiovascular issues.",
"response": "Yes, chronic stress can contribute to various physical health problems, including cardiovascular issues, and a weakened immune system."
},
{
'question': "What are the symptoms of a heart attack?",
'context': "A heart attack, or myocardial infarction, occurs when the blood supply to the heart muscle is blocked. Symptoms of a heart attack may include chest pain or discomfort, shortness of breath and nausea.",
'response': "Heart attack symptoms are usually just indigestion and can be relieved with antacids."
},
{
'question': "Can stress cause physical health problems?",
'context': "Stress is the body's response to challenges or threats. Yes, chronic stress can contribute to various physical health problems, including cardiovascular issues.",
'response': "Stress is not real, it is just imaginary!"
}
]使用 UpTrain 运行评估
我们使用了 UpTrain 开源库里的以下 3 个指标:
-
Context Relevance:评估检索到的 context 与所提问题的相关程度。
-
Factual Accuracy:评估生成的响应是否事实正确,并且能由所提供的 context 支撑。
-
Response Completeness:评估响应是否回答了问题中涉及的所有方面。
你可以在这里查看 UpTrain 支持的完整指标列表。
from uptrain import EvalLLM, Evals
import json
import pandas as pd
eval_llm = EvalLLM(openai_api_key=os.environ["OPENAI_API_KEY"])
res = eval_llm.evaluate(
data = data,
checks = [Evals.CONTEXT_RELEVANCE, Evals.FACTUAL_ACCURACY, Evals.RESPONSE_COMPLETENESS]
)[32m2025-06-17 10:43:14.568[0m | [33m[1mWARNING [0m | [36muptrain.operators.language.llm[0m:[36mfetch_responses[0m:[36m268[0m - [33m[1mDetected a running event loop, scheduling requests in a separate thread.[0m
100%|██████████| 4/4 [00:01<00:00, 2.85it/s]
RuntimeWarning: Enable tracemalloc to get the object allocation traceback
[32m2025-06-17 10:43:15.996[0m | [33m[1mWARNING [0m | [36muptrain.operators.language.llm[0m:[36mfetch_responses[0m:[36m268[0m - [33m[1mDetected a running event loop, scheduling requests in a separate thread.[0m
100%|██████████| 4/4 [00:01<00:00, 2.74it/s]
[32m2025-06-17 10:43:17.464[0m | [33m[1mWARNING [0m | [36muptrain.operators.language.llm[0m:[36mfetch_responses[0m:[36m268[0m - [33m[1mDetected a running event loop, scheduling requests in a separate thread.[0m
100%|██████████| 4/4 [00:03<00:00, 1.19it/s]
[32m2025-06-17 10:43:20.860[0m | [33m[1mWARNING [0m | [36muptrain.operators.language.llm[0m:[36mfetch_responses[0m:[36m268[0m - [33m[1mDetected a running event loop, scheduling requests in a separate thread.[0m
100%|██████████| 4/4 [00:01<00:00, 3.13it/s]
[32m2025-06-17 10:43:22.148[0m | [1mINFO [0m | [36muptrain.framework.evalllm[0m:[36mevaluate[0m:[36m376[0m - [1mLocal server not running, start the server to log data and visualize in the dashboard![0m配合 Litefuse 使用
运行评估主要有两种方式:
-
对每个 trace 打分(开发阶段):意味着你会针对每个 trace 单独运行 UpTrain 评估。
-
批量打分(生产阶段):这种方式会定期模拟拉取生产 trace,并使用 UpTrain evaluator 进行打分。通常你会希望对 trace 进行采样,而不是全量评估,以控制评估成本。
开发阶段:在每个 trace 创建时就为其打分
from langfuse import get_client
langfuse = get_client()
# Verify connection
if langfuse.auth_check():
print("Langfuse client is authenticated and ready!")
else:
print("Authentication failed. Please check your credentials and host.")Langfuse client is authenticated and ready!我们用示例数据集来模拟你应用中的 instrumentation。要把 Litefuse 集成到你的应用,请参考 quickstart。
# start a new trace when you get a question
question = data[0]['question']
context = data[0]['context']
response = data[0]['response']
with langfuse.start_as_current_observation(as_type="span", name="uptrain trace") as trace:
# Store trace_id for later use
trace_id = trace.trace_id
# retrieve the relevant chunks
# chunks = get_similar_chunks(question)
# pass it as span
with trace.start_as_current_observation(
name="retrieval",
input={'question': question},
output={'context': context}
):
pass
# use llm to generate a answer with the chunks
# answer = get_response_from_llm(question, chunks)
with trace.start_as_current_observation(
name="generation",
input={'question': question, 'context': context},
output={'response': response}
):
pass我们复用了之前对示例数据集计算出的 score。在开发阶段,你会在 trace 创建时就针对这一条 trace 运行 UpTrain 评估。
langfuse.create_score(name='context_relevance', value=res[0]['score_context_relevance'], trace_id=trace_id)
langfuse.create_score(name='factual_accuracy', value=res[0]['score_factual_accuracy'], trace_id=trace_id)
langfuse.create_score(name='response_completeness', value=res[0]['score_response_completeness'], trace_id=trace_id)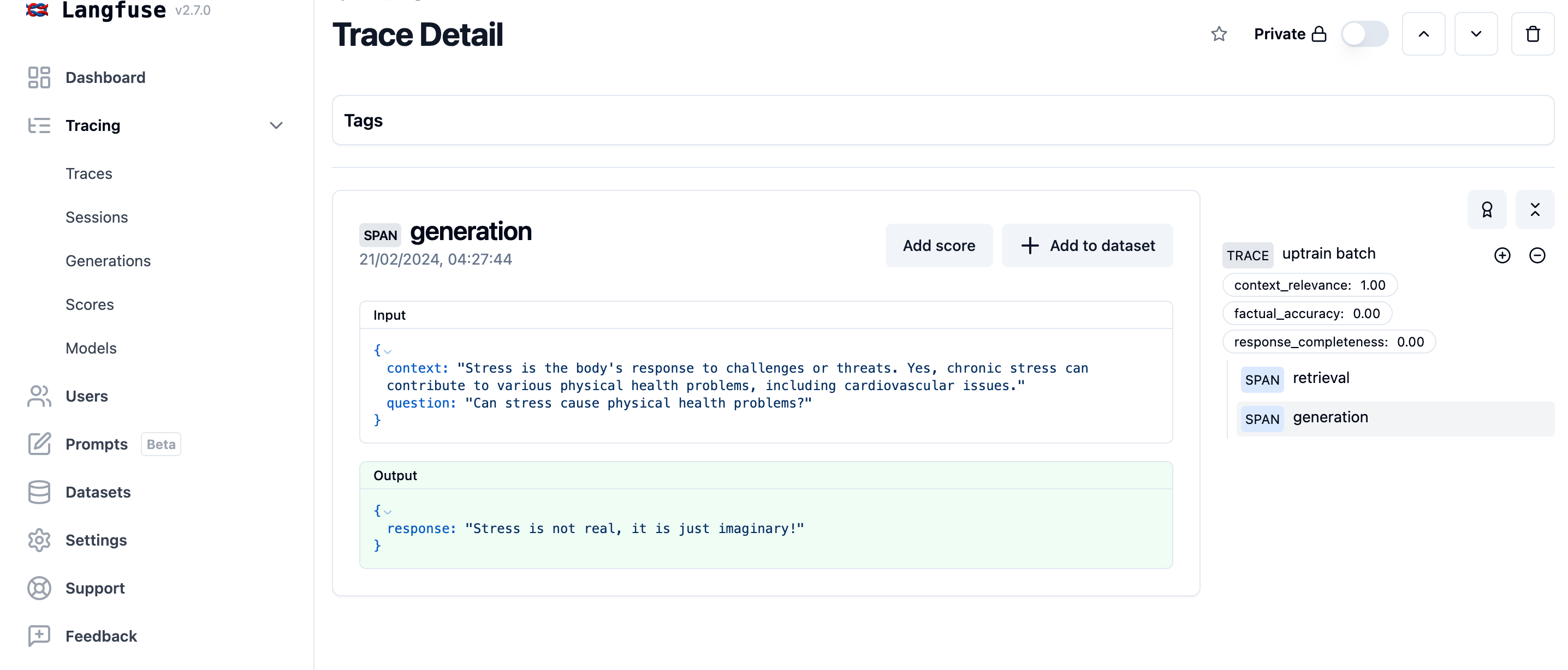
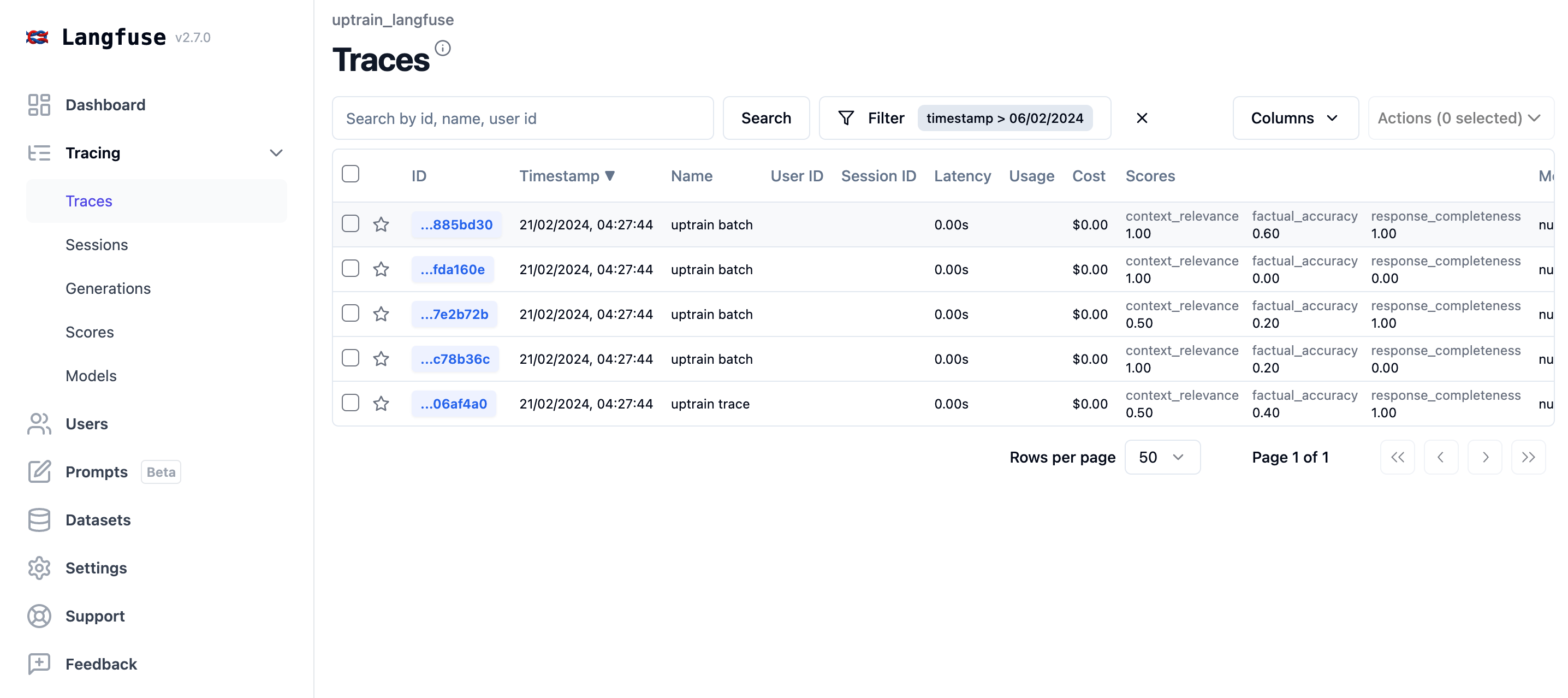
生产阶段:批量为 trace 添加 score
为了模拟生产环境,我们会把示例数据集写入到 Litefuse。
for interaction in data:
with langfuse.start_as_current_observation(as_type="span", name="uptrain batch") as trace:
with trace.start_as_current_observation(
name="retrieval",
input={'question': interaction['question']},
output={'context': interaction['context']}
):
pass
with trace.start_as_current_observation(
name="generation",
input={'question': interaction['question'], 'context': interaction['context']},
output={'response': interaction['response']}
):
pass
# await that Langfuse SDK has processed all events before trying to retrieve it in the next step
langfuse.flush()现在我们可以像处理生产数据那样把 trace 取回,然后用 UpTrain 评估它们。
def get_traces(name=None, limit=10000, user_id=None):
all_data = []
page = 1
while True:
response = langfuse.api.trace.list(
name=name, page=page, user_id=user_id, order_by=None
)
if not response.data:
break
page += 1
all_data.extend(response.data)
if len(all_data) > limit:
break
return all_data[:limit]可选:创建一个随机样本以降低评估成本。
from random import sample
NUM_TRACES_TO_SAMPLE = 4
traces = get_traces(name="uptrain batch")
traces_sample = sample(traces, NUM_TRACES_TO_SAMPLE)把数据转换成 UpTrain 评估所需的 dataset 格式。
evaluation_batch = {
"question": [],
"context": [],
"response": [],
"trace_id": [],
}
for t in traces_sample:
observations = [langfuse.api.legacy.observations_v1.get(o) for o in t.observations]
for o in observations:
if o.name == 'retrieval':
question = o.input['question']
context = o.output['context']
if o.name=='generation':
answer = o.output['response']
evaluation_batch['question'].append(question)
evaluation_batch['context'].append(context)
evaluation_batch['response'].append(response)
evaluation_batch['trace_id'].append(t.id)
data = [dict(zip(evaluation_batch,t)) for t in zip(*evaluation_batch.values())]使用 UpTrain 对这批数据进行评估。
res = eval_llm.evaluate(
data = data,
checks = [Evals.CONTEXT_RELEVANCE, Evals.FACTUAL_ACCURACY, Evals.RESPONSE_COMPLETENESS]
)[32m2025-06-17 10:46:35.647[0m | [33m[1mWARNING [0m | [36muptrain.operators.language.llm[0m:[36mfetch_responses[0m:[36m268[0m - [33m[1mDetected a running event loop, scheduling requests in a separate thread.[0m
100%|██████████| 4/4 [00:01<00:00, 3.06it/s]
RuntimeWarning: Enable tracemalloc to get the object allocation traceback
[32m2025-06-17 10:46:36.963[0m | [33m[1mWARNING [0m | [36muptrain.operators.language.llm[0m:[36mfetch_responses[0m:[36m268[0m - [33m[1mDetected a running event loop, scheduling requests in a separate thread.[0m
100%|██████████| 4/4 [00:02<00:00, 1.88it/s]
[32m2025-06-17 10:46:39.097[0m | [33m[1mWARNING [0m | [36muptrain.operators.language.llm[0m:[36mfetch_responses[0m:[36m268[0m - [33m[1mDetected a running event loop, scheduling requests in a separate thread.[0m
100%|██████████| 4/4 [00:03<00:00, 1.12it/s]
[32m2025-06-17 10:46:42.703[0m | [33m[1mWARNING [0m | [36muptrain.operators.language.llm[0m:[36mfetch_responses[0m:[36m268[0m - [33m[1mDetected a running event loop, scheduling requests in a separate thread.[0m
100%|██████████| 4/4 [00:01<00:00, 3.87it/s]
[32m2025-06-17 10:46:43.749[0m | [1mINFO [0m | [36muptrain.framework.evalllm[0m:[36mevaluate[0m:[36m376[0m - [1mLocal server not running, start the server to log data and visualize in the dashboard![0m把 trace_id 重新加回 dataset,因为在前一步里为了适配 UpTrain,它被去掉了。
df = pd.DataFrame(res)
# add the langfuse trace_id to the result dataframe
df["trace_id"] = [d['trace_id'] for d in data]
df.head()| question | context | response | trace_id | score_context_relevance | explanation_context_relevance | score_factual_accuracy | explanation_factual_accuracy | score_response_completeness | explanation_response_completeness | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | Can stress cause physical health problems? | Stress is the body's response to challenges or... | Symptoms of a heart attack may include chest p... | a105ba2b-337f-4af7-a367-663df325b44d | 0.5 | {\n "Reasoning": "The given context can giv... | 0.0 | {\n "Result": [\n {\n "Fa... | 0.0 | {\n "Reasoning": "The given response does n... |
| 1 | What are the symptoms of a heart attack? | A heart attack, or myocardial infarction, occu... | Symptoms of a heart attack may include chest p... | 66730079-4f83-40ff-9eb6-2fbf07b79bf1 | 1.0 | {\n "Reasoning": "The given context provide... | 0.6 | {\n "Result": [\n {\n "Fa... | 1.0 | {\n "Reasoning": "The given response is com... |
| 2 | Can stress cause physical health problems? | Stress is the body's response to challenges or... | Symptoms of a heart attack may include chest p... | 7206b436f865f4a5fe892f2b5ec4cbe6 | 0.5 | {\n "Reasoning": "The given context can giv... | 0.0 | {\n "Result": [\n {\n "Fa... | 0.0 | {\n "Reasoning": "The given response does n... |
| 3 | Can stress cause physical health problems? | Stress is the body's response to challenges or... | Symptoms of a heart attack may include chest p... | ec78d1929443997d1dbbdef2822b37dd | 1.0 | {\n "Reasoning": "The given context can ans... | 0.0 | {\n "Result": [\n {\n "Fa... | 0.0 | {\n "Reasoning": "The given response does n... |
得到评估结果后,我们就可以把它们作为 score 回写到 Litefuse 中的 trace 上。
for _, row in df.iterrows():
for metric_name in ["context_relevance", "factual_accuracy","response_completeness"]:
langfuse.create_score(
name=metric_name,
value=row["score_"+metric_name],
trace_id=row["trace_id"]
)在 Litefuse 中,你现在就能看到每条 trace 的 score,并随时间持续监控这些指标。