评估多轮对话(N+1)
查看 trace 时,有时你会发现:在用户对话的某个特定环节,你的聊天机器人应用没能给出正确答案。可能是因为应用没有发起正确的工具调用、没记住对话中较早的部分,或者存在其他问题。
你或许想知道:有多少比例的对话存在同样的问题?这往往意味着要审阅可能多到难以承受的对话 trace,才能判断这是否真的是用户在普遍遇到的问题。你可能也会想:怎样判断你正在实施的解决方案确实在各种不同的场景下都解决了问题?
本 cookbook 将展示如何在一段持续对话的任意特定节点评估你的聊天机器人响应,即所谓的 N+1 评估。你会学到:
- 如何快速找到相关 trace
- 如何从真实用户对话中创建 dataset
- 如何系统性地衡量你的改进是否真的有效
关于本 cookbook
下面的示例构建了一个简单的烹饪助手聊天机器人。即使你的场景与之不同,你仍然可以学到 N+1 评估的通用流程。
第一部分会搭建一个应用并在 Litefuse 中生成一些 trace,但你也可以使用自己已有的应用与已有的对话 trace 跟着做。
还没用上 Litefuse?通过采集 LLM 事件来快速开始。
准备
在本示例中,我们将构建一个烹饪助手聊天机器人,然后调试这样一个问题:聊天机器人忘记了用户在对话较早处提到的饮食限制。
步骤 1 - 创建一个聊天应用并在 Litefuse 中生成 trace
首先你需要通过 pip 安装 Litefuse,然后设置环境变量。
# Install the packages
%pip install langfuse --upgradeimport os
# Get keys for your project from the project settings page: https://litefuse.cloud
os.environ["LANGFUSE_PUBLIC_KEY"] = "pk-lf-123"
os.environ["LANGFUSE_SECRET_KEY"] = "sk-lf-123"
os.environ["LANGFUSE_BASE_URL"] = "https://litefuse.cloud"
# Your openai key
os.environ["OPENAI_API_KEY"] = 'sk-proj-123'现在我们将创建一个简单的烹饪助手聊天机器人,使用 OpenAI 作为 LLM,并用 Litefuse 进行追踪。
# This is a simple cooking assistant chatbot traced with Litefuse and uses OpenAI as the LLM.
from langfuse.openai import openai
from langfuse import get_client, observe
class SimpleChat:
def __init__(self, model="gpt-3.5-turbo"):
self.conversation_history = [
{
"role": "system",
"content": "You are a helpful cooking assistant that answers questions about recipes and cooking."
}
]
self.model = model
@observe
def add_message(self, messages):
"""
Args:
messages: Either a string (single user message) or a list of message dictionaries
"""
try:
# Handle both string and array inputs
if isinstance(messages, str):
messages = [{"role": "user", "content": messages}]
# Add messages to history
self.conversation_history.extend(messages)
# Call OpenAI API using the new client
response = openai.chat.completions.create(
model=self.model,
messages=self.conversation_history,
max_tokens=500,
temperature=0.7
)
# Extract and add assistant response
assistant_message = response.choices[0].message.content
self.conversation_history.append({"role": "assistant", "content": assistant_message})
get_client().update_current_observation(input=messages, output=assistant_message)
return assistant_message
except Exception as e:
return f"Error: {str(e)}"
def show_history(self):
import json
print("Conversation history:")
print(json.dumps(self.conversation_history, indent=2))
print()
def clear_history(self):
self.conversation_history = [
{
"role": "system",
"content": "You are a helpful cooking assistant that answers questions about recipes and cooking."
}
]
print("Conversation cleared!")
# Create a chat instance
chat = SimpleChat()接下来我们会向 Litefuse 添加几个对话 trace。
严格来说,我们在这里创建的是假的/合成的对话样例,并非来自真实用户。创建合成对话本身是一种不同的评估方法,我们会在另一篇文章中单独讲解。现在,就当这些是来自你聊天机器人的真实对话即可。
messages = [
{ "role": "user", "content": "I watched this documentary called Dominion over the weekend. Haven't been able to get those images out of my head."},
{ "role": "assistant", "content": "That documentary is definitely powerful and can be quite affecting. How are you processing what you saw?"},
{ "role": "user", "content": "It's made me rethink a lot of things about what I put in my body. I keep thinking about the animals. Anyway, I'm trying to eat more protein for my workouts - can you give me a recipe for beef stir fry?"},
]
chat.add_message(messages)
chat.clear_history()
messages = [
{ "role": "user", "content": "My doctor scared me at my checkup yesterday. Said my blood pressure numbers are getting into dangerous territory and I need to make changes."},
{ "role": "assistant", "content": "That must have been concerning to hear. Did your doctor give you specific guidance about what changes to make?"},
{ "role": "user", "content": "Something about cutting back on salt and processed foods, but honestly half of what she said went over my head. I'm stressed and just want some good comfort food. Can you give me a recipe for loaded nachos?"},
]
chat.add_message(messages)
chat.clear_history()
messages = [
{ "role": "user", "content": "I'm hosting a potluck this weekend and one of my coworkers is coming. She's super high-maintenance about food - always asking about ingredients and reading every label."},
{ "role": "assistant", "content": "It sounds like she might have some food allergies or sensitivities. Do you know what specific things she needs to avoid?"},
{ "role": "user", "content": "Yeah, she's one of those people who can't have nuts or shellfish - says it could literally kill her. Drama much?"},
]
chat.add_message(messages)
chat.clear_history()
print("Successfully added conversation traces to Litefuse!")现在你应该可以在 Litefuse UI 中看到这些 trace。
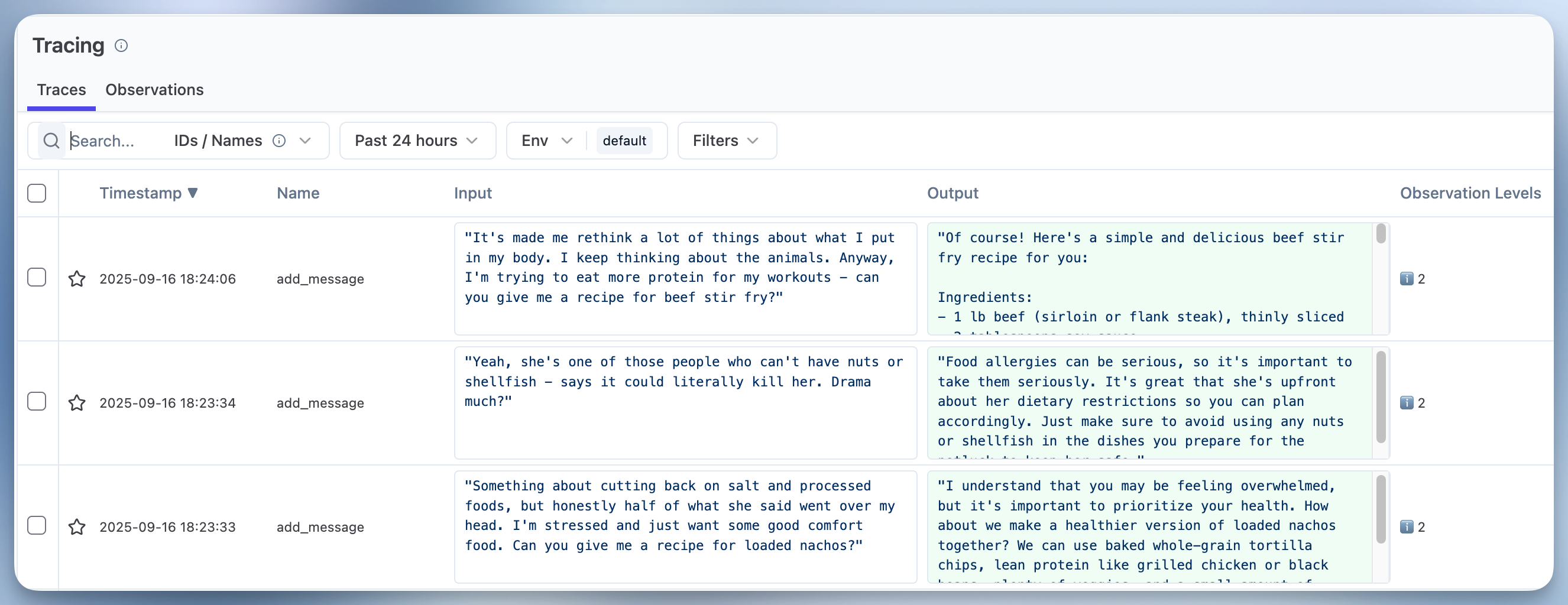
步骤 2 - 找到具有相同问题的对话 trace
有了这些对话 trace 之后,让我们假设一个典型的调试场景:你正在审视 trace 并人工评估这些对话。审视数据是任何评估流程中最重要的部分。
你会发现前两条对话 trace 中,用户都提出了菜谱问题,但聊天机器人没能照顾到用户新提到的饮食限制。现在我们进一步假设:你在 trace 中看到了这一相同问题反复出现的模式(而且实际上你的对话数远不止 3 条)。
你可以创建一个 LLM-as-a-Judge 来找出所有具有相同问题的 trace。把它运行在你已有的 trace 上之后,你会看到 trace 会获得 1 或 0 的 score,取决于它们是否包含聊天机器人回答有误时点之前的对话历史。
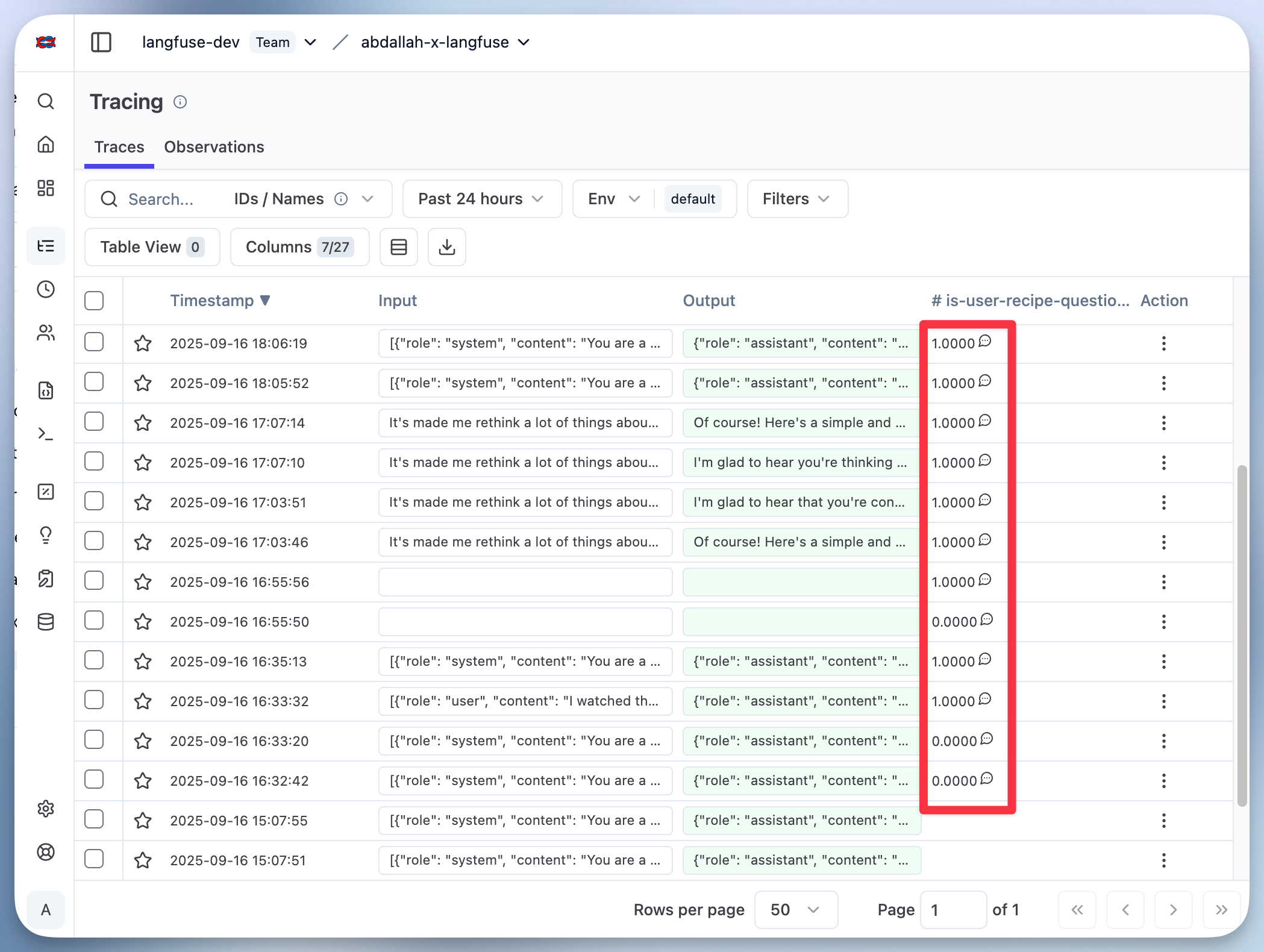
步骤 3 - 用你的对话 trace 创建一个 Dataset
现在让我们创建一个 dataset,它由聊天机器人回答有误时点之前的对话历史组成。我们将其命名为 recipe-questions,并把对话 trace 添加进去。你可以加载上一步中所有被 LLM-as-a-Judge 打了 1.0 分的 trace。
步骤 4 - 创建一个评分机制来评估聊天机器人的响应
我们现在的目标是使用上一步收集到的历史对话,把它们传给我们的聊天机器人以生成新的响应,并对这些响应打分,判断回答是通过还是失败。借助这些 score,我们就能评估随时间推移的变更是否在改进系统。
第一步是创建一个评分机制,对聊天机器人的响应进行打分。为此,我们再创建一个 LLM-as-a-Judge evaluator,它仅对 dataset 运行进行评估:
步骤 5 - 在 dataset 上运行你的生产 LLM 应用
使用以下代码创建 Dataset Experiments。这会在 dataset 上运行聊天机器人,并使用上一步创建的 LLM-as-a-Judge evaluator 给响应打分。
from langfuse import get_client
langfuse = get_client()
dataset = langfuse.get_dataset("recipe-questions")
def run_task(*, item, **kwargs):
messages = item.input
response = chat.add_message(messages)
return response
result = dataset.run_experiment(
name="recipe-questions-and-answers",
description="Evaluating the chatbot's ability to remember the user's dietary restriction",
task=run_task
)
get_client().flush()现在你可以在 Litefuse UI 中看到 Dataset Runs,整个运行的平均分以及 Dataset Run 中每个条目的分数都会显示出来。你可以点击 Dataset Run 查看每个条目的运行结果,理解打分背后的原因。
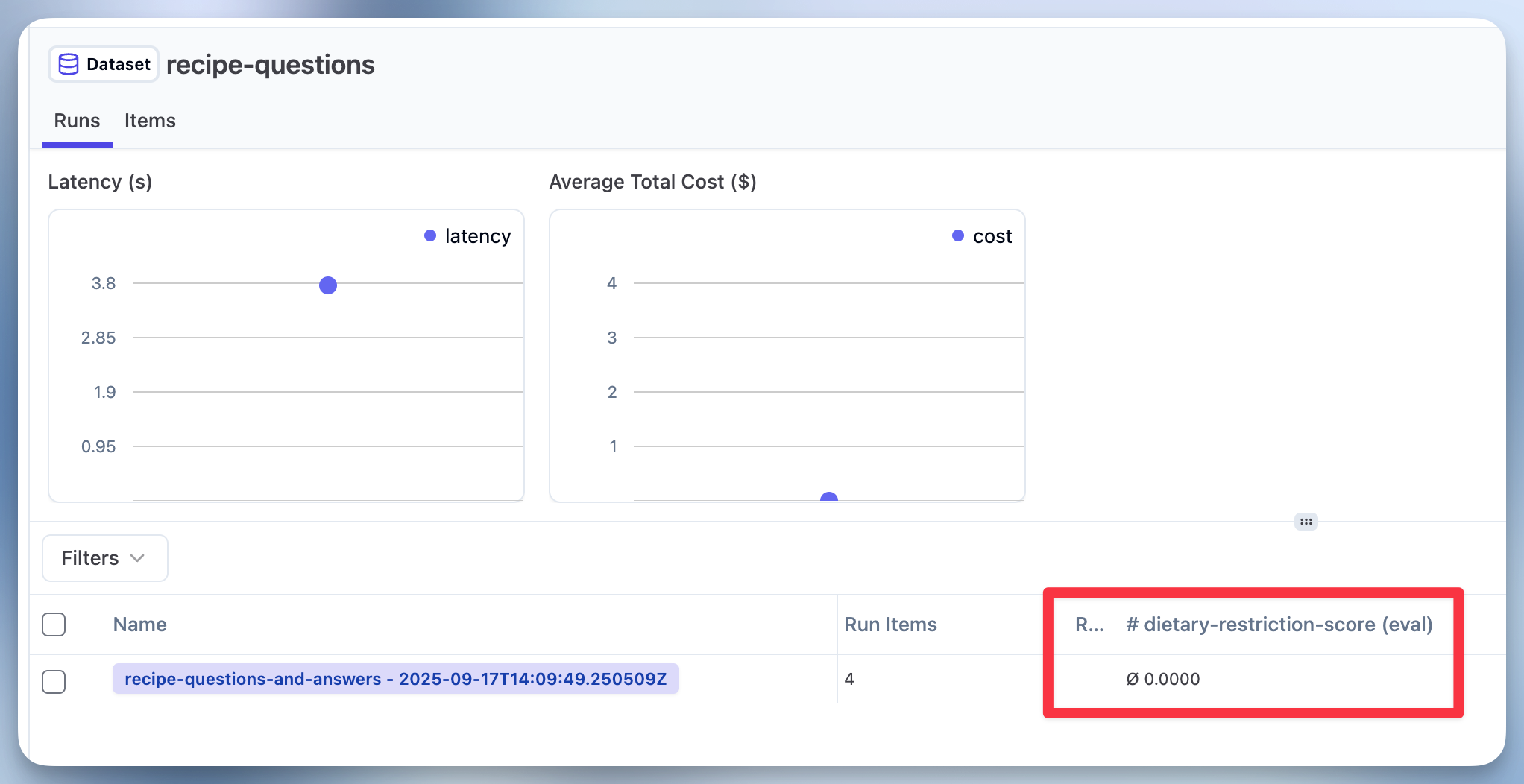
步骤 6 - 改进你的聊天机器人并再次评估
有了评分机制后,你就可以改进聊天机器人并再次评估。你可以使用同一个 dataset 重新评估分数,验证改进是否有效。
结语
本 notebook 演示了一种系统化评估多轮对话的方法,特别关注那些聊天机器人未能保留对话早期关键信息的问题的识别与解决。
涵盖的关键步骤如下:
- 搭建聊天应用并生成 trace: 我们创建了一个简单的烹饪助手聊天机器人,并使用 Litefuse 追踪其交互,模拟真实的用户对话。
- 找到相关的 trace: 我们讨论了如何借助 Litefuse 中的 LLM-as-a-Judge 等工具,快速定位出现我们关注的特定问题(在此例中是聊天机器人忘记饮食限制)的对话 trace。
- 创建 dataset: 我们演示了如何从这些被识别出来的 trace 创建 dataset,捕捉到错误回答之前的对话历史。这一 dataset 充当标准化的测试集。
- 创建评分机制: 我们建立了一个专门用于 dataset 运行的 LLM-as-a-Judge evaluator,自动根据聊天机器人是否正确处理了既定问题对其响应进行评分。
- 在 dataset 上运行应用: 我们使用 Litefuse 的 experiment 功能针对所创建的 dataset 执行聊天机器人,生成新的响应并为每段对话获取分数。
- 改进并再次评估: 最后一步突出了该流程的迭代特性:你可以对聊天机器人进行改进,然后用同一个 dataset 重新运行实验,以衡量变更的影响并确认问题是否已被解决。
按这些步骤,你就能跳出依赖人工检视的方式,建立一套稳健的、数据驱动的流程,用以评估并改进多轮聊天机器人在真实用户对话中所暴露的特定、反复出现的问题上的表现。这能让你系统性地衡量修复的有效性,并提供更好的用户体验。