LLM 应用意图分类
本指南演示如何利用 Litefuse 的 trace 数据构建一个意图分类 pipeline。无论是监督式还是无监督式方法,你都可以自动化地为 Litefuse 项目中的 trace 打标签并进行分析。
为什么这件事有价值?
- LLM 应用通常包含多种混合的意图
- 按意图拆分评估,有助于识别哪些 trace 在生产环境中表现不佳
- 衡量各意图的数量是有必要的,因为这样才能确保用于离线 / 开发评估的数据集能代表真实的生产用量
意图分类有两种思路:
- 监督式方法:你给模型提供带标签的训练数据,模型在预测时会输出预定义标签中的某一个。
- 无监督方法:模型尝试在数据中找到聚类,你随后再为这些聚类打上合适的标签。
读完这个 notebook 后,你将得到两条基础 pipeline,它们会:
- 从你的某个 Litefuse 项目中提取 trace 数据。
- 训练一个意图分类模型。
- 使用监督式和无监督方式预测 trace 的意图。
- 将预测出的意图作为 tag 写回 Litefuse。
感谢 @thompsgj 为 Litefuse 文档贡献了这个 notebook!
环境准备
先准备好运行环境。首先关闭一些不需要的告警:
import warnings
warnings.filterwarnings("ignore")安装必要的依赖包:
# Install Langfuse
%pip install --quiet "langfuse<3.0.0"
# Install dependencies for supervised intent classification
%pip install --quiet pandas scikit-learn sentence-transformers torch transformers
# Install dependencies for unsupervised intent recognition
%pip install --quiet chromadb hdbscan openai配置你的 Litefuse 项目凭据(可在 Litefuse 项目设置页 获取):
import os
# Get keys for your project from the project settings page
# https://litefuse.cloud
os.environ["LANGFUSE_PUBLIC_KEY"] = ""
os.environ["LANGFUSE_SECRET_KEY"] = ""
os.environ["LANGFUSE_BASE_URL"] = "https://litefuse.cloud"从 Sentence Transformers 库中选择一个 embedding 模型:
# Select embedding model
from sentence_transformers import SentenceTransformer
embedding_model = SentenceTransformer("all-mpnet-base-v2")监督式意图分类 pipeline(虚拟数据)
本节介绍如何基于 Litefuse trace 数据创建一个监督式意图分类模型。流程包括:拉取 trace 数据,使用 scikit-learn 和 sentence transformers 构建并训练模型,进行意图预测,并把标签写回 Litefuse。这种方法需要带标签的数据,但对预定义意图的预测结果保持一致,适合那些已经明确的意图识别场景。
1. 拉取 Litefuse trace
初始化 Langfuse 客户端:
from langfuse import Langfuse
langfuse = Langfuse()可选:创建虚拟 trace 数据
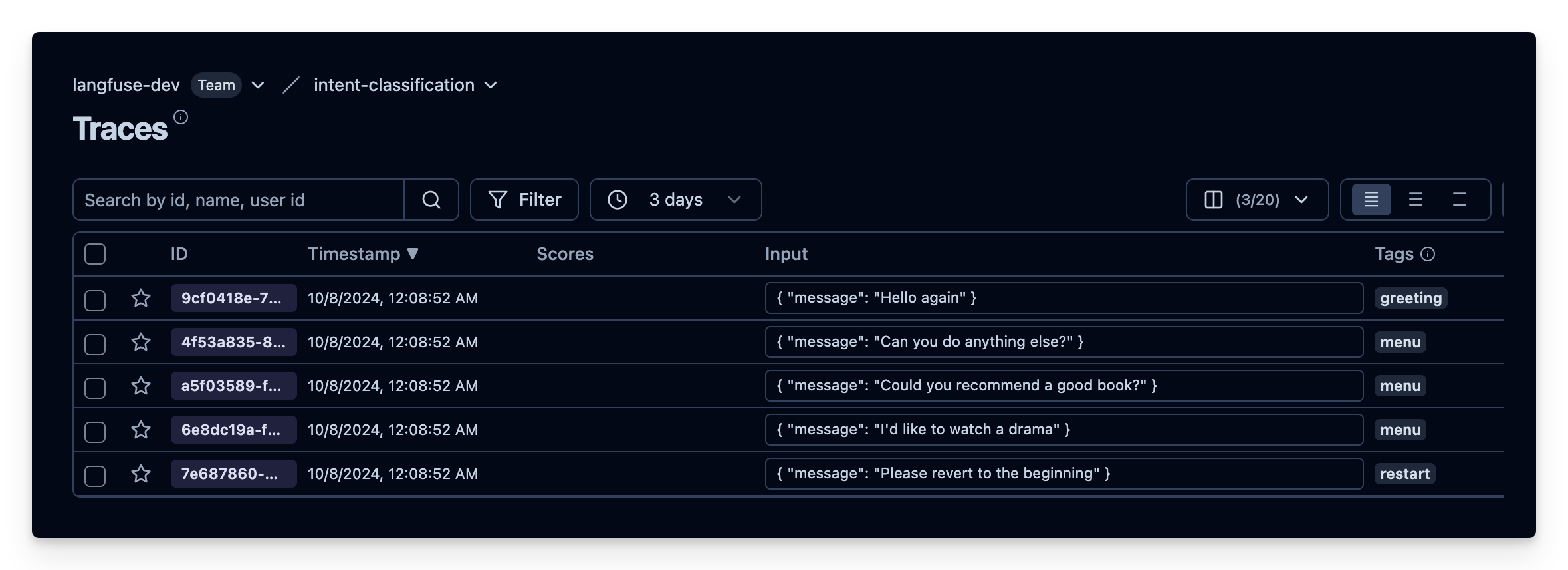
如果你的项目里还没有数据,可以运行接下来两个 cell 创建一些简单的虚拟 trace,用于跑通本 notebook。本节后续代码假定 trace 的 input 中包含 “message” 键。如果你用的是其他结构的数据,请相应调整 notebook。
sample_utterances = [
"Hello again",
"Can you do anything else?",
"Could you recommend a good book?",
"I'd like to watch a drama",
"Please revert to the beginning"
]
# Create dummy traces
for utterance in sample_utterances:
langfuse.trace(input={"message": utterance})从你的项目里取数据
traces = langfuse.fetch_traces()
traces.data[0].dict(){'id': '7e687860-55eb-47f0-b632-e568d5dfb57b',
'timestamp': datetime.datetime(2024, 10, 8, 7, 7, 51, 549000, tzinfo=datetime.timezone.utc),
'input': {'message': 'Please revert to the beginning'},
'tags': [],
'public': False,
'htmlPath': '/project/cm200q5d4003v6upt2pnmihyj/traces/7e687860-55eb-47f0-b632-e568d5dfb57b',
'latency': 0.0,
'totalCost': 0.0,
'observations': [],
'scores': [],
'bookmarked': False,
'projectId': 'cm200q5d4003v6upt2pnmihyj',
'createdAt': '2024-10-08T07:07:52.917Z',
'updatedAt': '2024-10-08T07:07:52.917Z',
'name': None,
'output': None,
'sessionId': None,
'release': None,
'version': None,
'userId': None,
'metadata': None,
'externalId': None}构造一个 DataFrame 便于分析:
traces_list = []
for trace in traces.data:
trace_info = [trace.id, trace.input["message"]]
traces_list.append(trace_info)
import pandas as pd
traces_df = pd.DataFrame(traces_list, columns=["trace_id", "message"])
traces_df.head()2. 构建并训练意图分类模型
准备一个小规模的带标签数据集:
import numpy as np
from sklearn.base import TransformerMixin, BaseEstimator
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import classification_report, accuracy_score
from sklearn.model_selection import train_test_split
from sklearn.pipeline import Pipeline
from tqdm.notebook import tqdm切分数据,并定义一个 embedding transformer:
# Note: This is a very small dataset.
# More data will help make the model more accurate and avoid overfitting.
sample_data = {
"text": [
# Greeting utterances
"hi",
"hello",
"howdy",
"hey there",
"greetings",
"Nice to see you",
"Let's start",
"begin",
"good morning",
"Good afternoon",
# Menu utterances
"I want to talk about something else",
"options",
"menu, please",
"Could we chat about another subject",
"I want to see the menu",
"switch topics",
"What else can you do",
"discuss about something else",
"Show me the menu",
"Can we do something else",
# Restart utterances
"restart",
"I'd like to do this again",
"let me try again",
"one more time",
"Can I review that?",
"check again",
"redo",
"again please",
"that was great, let's start from the beginning",
"go back to start",
],
"intent": [
"greeting",
"greeting",
"greeting",
"greeting",
"greeting",
"greeting",
"greeting",
"greeting",
"greeting",
"greeting",
"menu",
"menu",
"menu",
"menu",
"menu",
"menu",
"menu",
"menu",
"menu",
"menu",
"restart",
"restart",
"restart",
"restart",
"restart",
"restart",
"restart",
"restart",
"restart",
"restart",
]
}df = pd.DataFrame(sample_data)
df.head()X_train, X_test, y_train, y_test = train_test_split(
df["text"],
df["intent"],
test_size=0.5,
random_state=14
)class Encoder(BaseEstimator, TransformerMixin):
def __init__(self):
self.embedding_model = embedding_model
def transform(self, X):
return self.embedding_model.encode(list(X))
def fit(self, X, y=None):
return selfpipeline = Pipeline([
('encoder', Encoder()),
('clf', LogisticRegression()),
])pipeline.fit(X_train, y_train)y_pred = pipeline.predict(X_test)
y_predarray(['greeting', 'menu', 'menu', 'greeting', 'restart', 'greeting',
'restart', 'menu', 'greeting', 'greeting', 'restart', 'greeting',
'menu', 'menu', 'menu'], dtype=object)single_pred = pipeline.predict(["Please let's move on"])
single_predarray(['menu'], dtype=object)probas = pipeline.predict_proba(["Please let's move on"])
probasarray([[0.30275492, 0.39219684, 0.30504823]])confidence_score = float(np.max(probas, axis=1)[0])
confidence_score0.3921968431842116print("\nClassification Report:\n", classification_report(y_test, y_pred))Classification Report:
precision recall f1-score support
greeting 0.83 1.00 0.91 5
menu 0.67 1.00 0.80 4
restart 1.00 0.50 0.67 6
accuracy 0.80 15
macro avg 0.83 0.83 0.79 15
weighted avg 0.86 0.80 0.78 153. 在 trace 上跑预测
for index, row in traces_df.iterrows():
result = pipeline.predict([row["message"]])
probas = pipeline.predict_proba([row["message"]])
confidence_score = float(np.max(probas, axis=1)[0])
traces_df.at[index, "label"] = "".join(result)
traces_df.at[index, "confidence_score"] = confidence_score
traces_df4. 为 trace 打上标签
# Note: This will add to existing tags, not add duplicate tags.
for index, row in traces_df.iterrows():
if row["confidence_score"] > 0.30:
trace_id = row["trace_id"]
label = row["label"]
langfuse.trace(id=trace_id, tags = [label])Litefuse 中的 tag
无监督意图分类 pipeline(生产数据)
无监督意图分类 pipeline 演示如何在没有预定义类别的情况下,对 Litefuse 的 trace 数据进行聚类并打标签。它利用 embedding 技术、聚类算法以及 LLM 生成的标签来自动识别并标注意图,对没有标签的数据非常灵活,但一致性可能不如监督式方法。
我们将使用 公共 demo 项目(基于 Litefuse 文档的 RAG)的样本数据,来理解用户在与 demo 应用交互时最关心什么。
import os
# Get keys for your project from the project settings page
# https://litefuse.cloud
os.environ["LANGFUSE_PUBLIC_KEY"] = ""
os.environ["LANGFUSE_SECRET_KEY"] = ""
os.environ["LANGFUSE_BASE_URL"] = "https://litefuse.cloud"
# Your openai key
os.environ["OPENAI_API_KEY"] = ""langfuse = Langfuse()1. 从 Litefuse 拉取 trace
我们会拉取发送给 demo 应用的 15,000 条消息,用于形成有意义的聚类。
PAGES_TO_FETCH = 300
traces = []
for i in range(PAGES_TO_FETCH):
traces_page = langfuse.fetch_traces(page=i+1)
traces.extend(traces_page.data)traces_list = []
for trace in traces:
trace_info = [trace.id, trace.input]
traces_list.append(trace_info)import pandas as pd
cluster_traces_df = pd.DataFrame(traces_list, columns=["trace_id", "message"])
cluster_traces_df.dropna(inplace=True) # drop traces with message = None2. 对消息进行 embedding
# naive implementation (batch=1)
# cluster_traces_df["embeddings"] = cluster_traces_df["message"].map(embedding_model.encode)
# use batches to speed up embedding
from tqdm import tqdm
batch_size = 512 # Choose an appropriate batch size based on your model and hardware capabilities
messages = cluster_traces_df["message"].tolist()
embeddings = []
# Use tqdm to wrap your range function for the progress bar
for i in tqdm(range(0, len(messages), batch_size), desc="Encoding batches"):
batch = messages[i:i + batch_size]
batch_embeddings = embedding_model.encode(batch)
embeddings.extend(batch_embeddings)
cluster_traces_df["embeddings"] = embeddingsEncoding batches: 100%|██████████| 30/30 [00:32<00:00, 1.09s/it]3. 基于 embedding 进行聚类
import hdbscan
clusterer = hdbscan.HDBSCAN(min_cluster_size=10)
cluster_traces_df["cluster"] = clusterer.fit_predict(cluster_traces_df["embeddings"].to_list())cluster_traces_df["cluster"].value_counts().head(10).to_dict(){-1: 9005,
0: 544,
83: 438,
92: 396,
3: 298,
86: 215,
1: 155,
94: 147,
58: 146,
77: 133}4. 为各个聚类生成标签
import openai
# Note: Depending on the volume of data you are running,
# you may want to limit the number of utterances representing each group (ex. utterances_group[:5])
def generate_label(message_group):
prompt = f"""
# Task
Your goal is to assign an intent label that most accurately fits the given group of utterances.
You will only provide a single label, no explanation. The label should be snake cased.
## Example utterances
so long
bye
## Example labels
goodbye
end_conversation
Utterances: {message_group}
Label:
"""
response = openai.chat.completions.create(
model="gpt-4o-mini",
messages=[
{
"role": "user",
"content": prompt
}
],
max_tokens=50
)
return response.choices[0].message.content.strip()
for cluster in cluster_traces_df["cluster"].unique():
if cluster == -1:
continue
messages_in_cluster = cluster_traces_df[cluster_traces_df["cluster"] == cluster]["message"]
# sample if too many messages
if len(messages_in_cluster) > 50:
messages_in_cluster = messages_in_cluster.sample(50)
label = generate_label(messages_in_cluster)
cluster_traces_df.loc[cluster_traces_df["cluster"] == cluster, "cluster_label"] = label5. 查看聚类结果
cluster_traces_df["cluster_label"].value_counts().head(20).to_dict(){'greeting': 2199,
'number_identifier': 544,
'end_conversation': 489,
'what_is_litefuse': 358,
'test': 299,
'unknown': 177,
'who_are_you': 101,
'what_can_you_do': 86,
'define_litefuse': 71,
'litefuse_usage': 66,
'ask_name': 51,
'how_it_works': 50,
'weather_inquiry': 46,
'summarize': 44,
'greetings': 43,
'open_source_query': 42,
'affirmation': 41,
'compare_litefuse_langsmith': 37,
'affirmative': 35,
'trace_in_litefuse': 34}# explore the messages sent within a specific cluster
cluster_traces_df[cluster_traces_df["cluster_label"]=="trace_in_langfuse"].message.head(20).to_dict(){21: 'how can i use the langfuse.trace function ?',
828: 'What exactly is a trace in litefuse?',
1455: 'how does a trace look like in litefuse?',
1563: 'What litefuse uses to represent the traces/',
1744: 'i want to know about trace in litefuse',
1953: 'How does litefuse tracing work?',
2349: 'What is a trace in litefuse?',
2439: 'Hello! How exactly are traces created in litefuse',
3001: 'What is tracing in the context of Litefuse?',
3761: 'How does tracing work in Litefuse?',
4759: 'what is traces in simple language in litefuse',
4877: 'Hello, can you explain how does the tracing work in Litefuse?',
5547: 'What is a trace in Litefuse?',
5751: 'what is called traces in litefuse. explain clearly with eaxmple',
6508: 'how to trace using litefuse?',
6914: "what dose 'trace' means in litefuse",
6919: 'how do i look at traces in litefuse',
7275: 'what is tracing in Litefuse? what purpose does it serve?',
7585: 'what is a trace in litefuse and how to create it?',
7774: 'what is a trace in litefuse?'}6. 把聚类作为 tag 回写到 Litefuse
# add as labels back to Litefuse
for index, row in cluster_traces_df.iterrows():
if row["cluster"] != -1:
trace_id = row["trace_id"]
label = row["cluster_label"]
langfuse.trace(id=trace_id, tags=[label])总结
两种方法各有利弊。
监督式方法需要前期投入大量工作来准备一个规模合适的带标签数据集。在推理阶段,它只能输出训练时见过的标签,所以对新场景的覆盖能力较弱。但其推理结果是稳定一致的。
无监督方法在处理无标签数据时更加灵活,可以输出一些你事先没有定义过的新标签。但不同次运行之间标签可能不一致(例如 ‘hello’、‘greeting’、‘start_conversation’)。此外,聚类的粒度可能比你手动打标签时更松或更严。
把两种方法结合起来可能是最理想的:无监督的意图分类能帮你快速对大量数据形成整体认知,便于做初步的探索性分析。当你对 trace 数据越来越熟悉、样本越攒越多之后,再用你最关心的那些意图标签训练监督式模型并在你的数据上运行就更有价值。或者,你也可以利用存储在向量数据库中的 embedding 数据进行相似度搜索,把历史标签复用到新数据上!